Логистическая регрессия с использованием PyTorch
Логистическая регрессия — это хорошо известный алгоритм машинного обучения, который используется для решения задач двоичной классификации. Он является производным от алгоритма линейной регрессии, который имеет непрерывную выходную переменную, а логистическая регрессия может даже классифицировать более двух классов, слегка изменив ее. Мы рассмотрим концепцию логистической регрессии и то, как она реализована в PyTorch, полезной библиотеке для создания моделей машинного обучения и глубокого обучения.
Концепция логистической регрессии
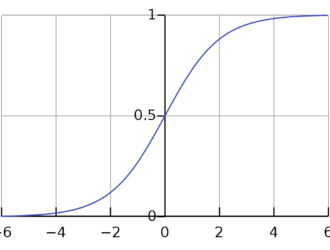
Логистическая регрессия — это алгоритм двоичной классификации. Это алгоритм принятия решений, что означает, что он устанавливает границы между двумя классами. Он расширяет проблему линейной регрессии, которая использует функцию активации на своих выходах, чтобы ограничить ее между 1 и 0. В результате это используется для задач двоичной классификации. График логистической регрессии выглядит как на рисунке ниже:

Мы можем видеть, что график ограничен между 0 и 1. Нормальная линейная регрессия может дать целевое значение в виде любого действительного числа, но это не относится к логистической регрессии из-за сигмоидной функции. Логистическая регрессия основана на концепции оценки максимального правдоподобия (MLE). Максимальная вероятность — это просто взять распределение вероятностей с заданным набором параметров и спросить: «Насколько вероятно, что я увижу эти данные, если бы мои данные были сгенерированы из этого распределения вероятностей?» Он работает, вычисляя вероятность для каждой отдельной точки данных, а затем умножая все эти вероятности вместе. На практике мы складываем логарифмы правдоподобия.
Если нам нужно построить модель машинного обучения, каждая точка данных независимой переменной будет иметь вид x1 * w1 + x2 * w2… и так далее, давая значение от 0 до 1 при передаче через функцию активации. Если мы возьмем 0,50 в качестве решающего фактора или порога. Тогда любой результат больше 0,5 рассматривается как 1, а любой результат меньше этого считается как 0.
Для более чем 2 классов мы используем подход One-Vs-All. One-Vs-All, также известный как One-Vs-Rest, представляет собой процесс классификации ML с несколькими ярлыками и классами. Он работает, сначала обучая двоичный классификатор для каждой категории, а затем подбирая каждый классификатор для каждого входа, чтобы определить, к какому классу принадлежит этот вход. Если у вашей задачи n классов, One-Vs-All преобразует ваш обучающий набор данных в n задач двоичной классификации.
Функция потерь, связанная с логистической регрессией, — это двоичная кросс-энтропия, которая является обратной по отношению к получению информации. Это также известно как потеря журнала имени. Функция потерь задается уравнением:

Что такое функция потерь?
Функция потерь — это математическая метрика, которую мы хотим уменьшить. Мы хотим построить модель, которая может точно предсказать то, что мы хотим, и один из способов измерить производительность модели — посмотреть на потери, поскольку мы знаем, какие результаты дает модель и что мы должны получить. Мы можем обучить и улучшить нашу модель, используя эту потерю и соответствующим образом корректируя параметры модели. Функции потерь различаются в зависимости от типа алгоритма. Для линейной регрессии популярными функциями потерь являются среднеквадратическая ошибка и средняя абсолютная ошибка, тогда как кросс-энтропия подходит для задач классификации.
Что такое функция активации?
Функции активации — это просто математические функции, которые изменяют входную переменную для получения нового выхода. Обычно это делается в машинном обучении, чтобы либо стандартизировать данные, либо ограничить ввод до определенного предела. Популярные функции действия — сигмовидная, выпрямленная линейная единица (ReLU), Tan (h) и т. д.
Что такое PyTorch?
Pytorch — популярная альтернатива глубокому обучению, работающая с Torch. Он был создан отделом искусственного интеллекта Facebook, но его можно использовать так же, как и другие варианты. Он используется для разработки множества моделей, но наиболее широко применяется в случаях использования обработки естественного языка (NLP). Pytorch — всегда отличный вариант, если вы хотите создавать модели с очень небольшим количеством ресурсов и хотите удобную, простую в использовании и легкую библиотеку для ваших моделей. Это также кажется естественным, что помогает завершить процесс. Мы будем использовать PyTorch для реализации наших моделей по указанным причинам. Однако алгоритм остается таким же с другими альтернативами, такими как Tensorflow.
Реализация логистической регрессии в PyTorch
Мы будем использовать следующие шаги для реализации нашей модели:
- Создайте нейронную сеть с некоторыми параметрами, которые будут обновляться после каждой итерации.
- Перебрать заданные входные данные.
- Входной сигнал будет проходить через сеть с использованием прямого распространения.
- Теперь мы рассчитаем потери, используя двоичную кросс-энтропию.
- Чтобы минимизировать функцию стоимости, мы обновляем параметры, используя градиентный спуск.
- Снова проделайте те же шаги, используя обновленные параметры.
Мы будем классифицировать цифры набора данных MNIST. Это популярная задача глубокого обучения, которой учат новичков.
Сначала импортируем необходимые библиотеки и модули.
import torch from torch.autograd import Variable import torchvision.transforms as transforms import torchvision.datasets as dsets
Следующим шагом будет импорт набора данных.
train = dsets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=False) test = dsets.MNIST(root='./data', train=False, transform=transforms.ToTensor())
Используйте загрузчик данных, чтобы сделать ваши данные повторяемыми
train_loader = torch.utils.data.DataLoader(dataset=train, batch_size=batch_size, shuffle=True) test_loader = torch.utils.data.DataLoader(dataset=test, batch_size=batch_size, shuffle=False)
Определите модель.
class Model(torch.nn.Module): def __init__(self, inp, out): super(Model, self).__init__() self.linear = torch.nn.Linear(inp, out) def forward(self, x): outputs = self.linear(x) return outputs
Укажите гиперпараметры, оптимизатор и потери.
batch = 50 n_iters = 1500 epochs = n_iters / (len(train_dataset) / batch) inp = 784 out = 10 alpha = 0.001 model = LogisticRegression(inp, out) loss = torch.nn.CrossEntropyLoss() optimizer = torch.optim.SGD(model.parameters(), lr=alpha)
Наконец, обучите модель.
itr = 0
for epoch in range(int(epochs)):
for i, (images, labels) in enumerate(train_loader):
images = Variable(images.view(-1, 28 * 28))
labels = Variable(labels)
optimizer.zero_grad()
outputs = model(images)
lossFunc = loss(outputs, labels)
lossFunc.backward()
optimizer.step()
itr+=1
if itr%500==0:
correct = 0
total = 0
for images, labels in test_loader:
images = Variable(images.view(-1, 28*28))
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total+= labels.size(0)
correct+= (predicted == labels).sum()
accuracy = 100 * correct/total
print("Iteration is {}. Loss is {}. Accuracy is {}.".format(itr, lossFunc.item(), accuracy))
Вывод
Мы рассмотрели объяснение логистической регрессии и ее реализации с помощью PyTorch, популярной библиотеки для разработки моделей глубокого обучения. Мы реализовали задачу классификации набора данных MNIST, в которой мы распознавали цифры на основе параметров изображений.
Редактор: AndreyEx




