Как найти уникальные данные в двух файлах в Linux
Вам сложно сравнить сходства и различия между двумя файлами в командной строке Linux? Не волнуйтесь, в этой статье мы расскажем, как выполнить эти задачи без использования сторонних инструментов, только с помощью встроенных команд.
Прежде чем продолжить, ознакомьтесь со следующими двумя файлами, которые мы будем использовать в качестве примеров для демонстрации всех команд, о которых пойдет речь в этой статье:
andreyex@linux: $ cat file1.txt 1 2 2 3 4 5 andreyex@linux: $ cat file2.txt 1 6 7 2 8 9 andreyex@linux: $
Как видно, ‘1‘ и ‘2‘ повторяются в обоих файлах, но, что удивительно, ‘2‘ встречается в первом файле несколько раз, а ‘3‘, ‘4‘, ‘5‘, ‘6‘, ‘7‘, ‘8‘, ‘9‘ — это различия между двумя файлами.
Итак, давайте посмотрим, как можно найти сходства и различия между этими двумя файлами с помощью терминала Linux.
Найдите общую строку в двух файлах
Первое, что нужно сделать, — найти общую строку в обоих файлах. Для этого можно использовать несколько команд Linux. В этой статье я сосредоточусь на двух командах: awk и grep.
Итак, чтобы найти в обоих файлах одинаковую строку, которая не повторяется, можно использовать следующую команду awk:
$ awk 'NR==FNR{a[$1]++;next} a[$1] ' file1.txt file2.txt
Выходной сигнал:
andreyex@linux:-$ awk 'NR==FNR{a[$1]++;next} a[$1] ' file1.txt file2.txt
1
2
andreyex@linux: $
Как видите, программа легко вывела общие строки ‘1‘ и ‘2‘ из обоих файлов. Чтобы понять, какие параметры мы использовали вместе с командой, ознакомьтесь со списком ниже.
NR==FNR{a[$1]++;next: Он сравнит два файла, разбив каждую строку на ключ в ассоциативном массиве, а затем увеличив значение для перехода к следующей строке.a[$1]: Это используется для обработки второго файла: если первое поле (в первом файле) текущей строки существует во втором файле, awk выводит эту строку.
Чтобы сравнить общую строку в двух файлах с помощью grep, используйте следующую команду:
$ grep -o -w -F -f file1.txt file2.txt | sort | uniq -c
Выходной сигнал:
andreyex@linux:-$ grep -o -w -F -f file1.txt file2.txt | sort | uniq -c 1 1 1 2 andreyex@linux: -$
Принимая во внимание,
-o: Это позволит выводить только совпадающие части строки, а не всю строку целиком.-w: Это позволяет сопоставлять только целые слова, а не подстроки в более длинных словах.-F: Это позволяет рассматривать шаблоны как фиксированные строки, а не как регулярные выражения, что удобно при поиске точных совпадений.-f file1.txt file.2.txt: Это файлы, которые будут использоваться для поиска шаблонов.sort: Эта команда используется для сортировки строк текста в алфавитном порядке.uniq -C: Эта команда используется для удаления повторяющихся строк из отсортированного файла и подсчета количества вхождений каждой уникальной строки.
Найдите различия между двумя файлами
Найти различия между двумя файлами — задача не из простых. Например, в обоих файлах встречается строка «2», но в первом файле она повторяется дважды, а во втором — один раз. Как вы думаете, что из этого можно считать сходством, а что — различием между этими двумя файлами?
Давайте выясним это с помощью команды diff, чтобы проверить, какие строки есть в первом файле, но отсутствуют во втором.
$ diff file1.txt file2.txt | grep '<' | cut -c 3
Выходной сигнал:
andreyex@linux: $ diff file1.txt file2.txt | grep '<' | cut -c 3 2 3 4 5 andreyex@linux: $
Как и ожидалось, дополнительная строка ‘2‘ считается разницей между этими двумя файлами. Таким образом, при сравнении двух файлов количество повторяющихся строк в них должно совпадать.
Давайте выясним, какие строки есть во втором файле, но отсутствуют в первом, с помощью команды comm:
$ comm -13 <(sort file1.txt) <(sort file2.txt)
Выходной сигнал:
andreyex@linux: $ comm -13 <(sort file1.txt) <(sort file2.txt) 6 7 8 9 andreyex@linux: $
На этот раз, как вы могли заметить, в выводе не появилось ‘2‘. Вместо этого мы получили ‘6‘, ‘7‘, ‘8‘ и ‘9‘, которых нет в первом файле. ‘2‘ не появилось, потому что во втором файле оно встречается только один раз. Таким образом, при сравнении файлов считается, что в них больше сходств, чем различий.
Наконец, давайте с помощью следующей команды найдем все различные строки, повторяющиеся в обоих файлах:
$ comm -3 <(sort file1.txt) <(sort file2.txt) | tr -d '\t'
Выходной сигнал:
andreyex@linux:-$ comm -3 <(sort file1.txt) <(sort file2.txt) | tr -d '\t' 2 3 4 5 6 7 8 9 andreyexglinux: $
Как видите, мы сразу увидели разницу между первым и вторым файлами, которых нет в файлах друг друга, включая дополнительный символ 2, который дважды повторяется в первом файле.
Найдите сходства и различия между двумя файлами с помощью Vim
Существует множество инструментов с графическим интерфейсом, которые помогут вам легко найти сходства и различия между двумя файлами без необходимости запоминать длинные команды, о которых мы говорили ранее.
Теперь вместо этих инструментов с графическим интерфейсом я предпочитаю использовать редактор Vim, в котором есть функции, позволяющие быстро находить сходства и различия между двумя файлами в наглядном формате.
$ vimdiff file1.txt file2.txt
#или
$ vim -d file1.txt file2.txt
Выходной сигнал:
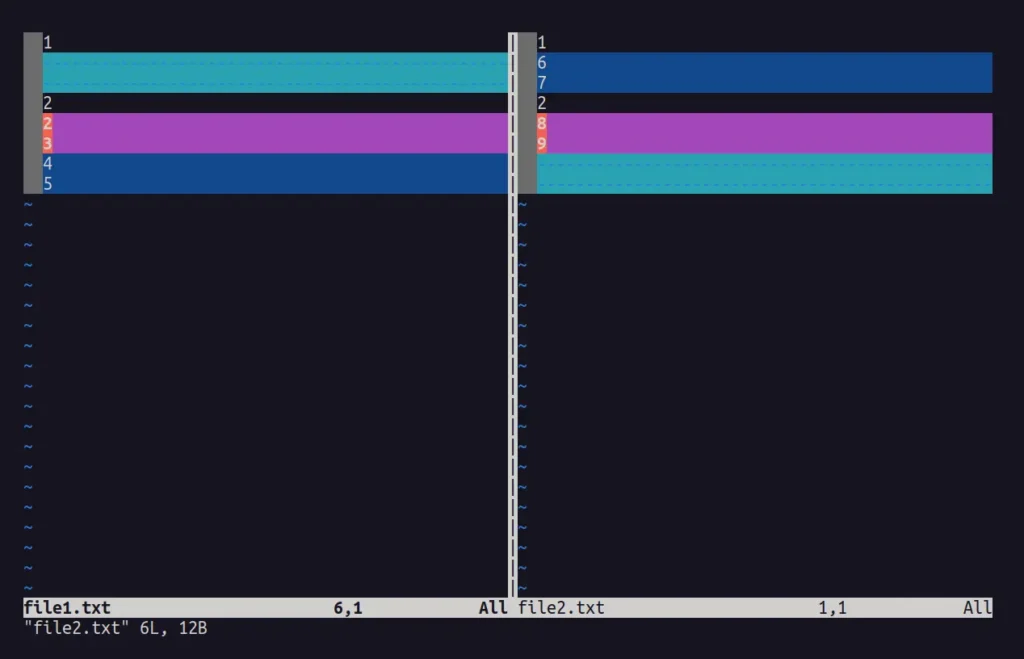
Повторяющиеся строки расположены друг напротив друга, а различия либо оставлены пустыми, либо выделены красным.
Вот и всё, на этом статья заканчивается. Надеюсь, сегодня вы узнали что-то новое. Напишите в комментариях, о чём бы вы хотели прочитать в следующий раз.
Редактор: AndreyEx




