Как описать таблицу в PostgreSQL?

Для описания таблиц базы данных нам не нужны какие-либо разрешения или привилегии пользователя. Кто угодно может описать информацию о таблице. «Описание таблицы в postgresql» относится к проверке структуры таблицы. Мы можем использовать различные примеры с разнообразием их использования, чтобы получить описание данных. Это вы поймете при чтении статьи.
Основной синтаксис, используемый для этой цели:
\d table-name; \d+ table-name;

Начнем обсуждение с описания таблицы. Откройте psql и укажите пароль для подключения к серверу.
Предположим, мы хотим описать все таблицы в базе данных либо в схеме системы, либо в пользовательских отношениях. Все они упоминаются в результате данного запроса.
>> \d

В таблице отображается схема, имена таблиц, тип и владелец. Схема всех таблиц является «общедоступной», потому что каждая созданная таблица хранится там. Столбец типа таблицы показывает, что некоторые из них являются «последовательными»; это таблицы, которые создает система. Первый тип — это «представление», поскольку это отношение представляет собой представление двух таблиц, созданных для пользователя. «Представление» — это часть любой таблицы, которую мы хотим сделать видимой для пользователя, в то время как другая часть скрыта от пользователя.
«\d» — это команда метаданных, используемая для описания структуры соответствующей таблицы.
Точно так же, если мы хотим упомянуть только описание пользовательской таблицы, мы добавляем «t» в предыдущей команде.
>> \dt

Вы можете видеть, что все таблицы имеют тип данных «таблица». Вид и последовательность удаляются из этого столбца. Чтобы увидеть описание конкретной таблицы, мы добавляем имя этой таблицы с помощью команды «\d».
В psql мы можем получить описание таблицы с помощью простой команды. Это описывает каждый столбец таблицы с типом данных каждого столбца. Предположим, у нас есть отношение с именем «технология», содержащее 4 столбца.
>> \d technology;

Есть некоторые дополнительные данные по сравнению с предыдущими примерами, но все они не имеют значения для этой таблицы, которая определяется пользователем. Эти 3 столбца связаны с внутренней схемой системы.
Другой способ получить подробное описание таблицы — использовать ту же команду со знаком «+».
>> \d+ technology;

Эта таблица показывает имя столбца и тип данных с хранением каждого столбца. Емкость хранилища разная для каждого столбца. «Обычный» показывает, что тип данных имеет неограниченное значение для целочисленного типа данных. Принимая во внимание, что в случае символа (10) он показывает, что мы предоставили ограничение, поэтому хранилище помечено как «расширенное», это означает, что сохраненное значение может быть расширено.
Последняя строка в описании таблицы «Метод доступа: куча» показывает процесс сортировки. Мы использовали «процесс кучи» для сортировки, чтобы получить данные.
В этом примере описание как-то ограничено. Для улучшения мы заменяем имя таблицы в данной команде.
>> \d info
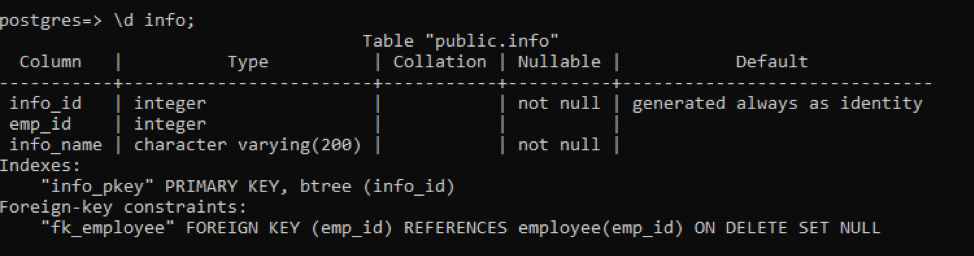
Вся отображаемая информация аналогична результирующей таблице. В отличие от этого, есть некоторая дополнительная функция. Столбец «Nullable» показывает, что два столбца таблицы описаны как «не пустые». А в столбце «по умолчанию» мы видим дополнительную функцию «всегда генерируется как идентификатор». Он считается значением по умолчанию для столбца при создании таблицы.
После создания таблицы отображается некоторая информация, которая показывает количество индексов и ограничения внешнего ключа. Индексы показывают «info_id» как первичный ключ, тогда как часть ограничений отображает внешний ключ из таблицы «employee».
До сих пор мы видели описание таблиц, которые уже были созданы ранее. Мы создадим таблицу с помощью команды «создать» и посмотрим, как столбцы добавляют атрибуты.
>> create table items ( id integer, name varchar(10), category varchar(10), order_no integer, address varchar(10), expire_month varchar(10));

Вы можете видеть, что каждый тип данных упоминается вместе с именем столбца. Некоторые из них имеют размер, тогда как другие, включая целые числа, представляют собой простые типы данных. Как и в случае с оператором create, теперь мы будем использовать оператор insert.
>> insert into items values (7, ‘sweater’, ‘clothes’, 8, ‘Lahore’);

Мы отобразим все данные таблицы с помощью оператора select.
select * from items;
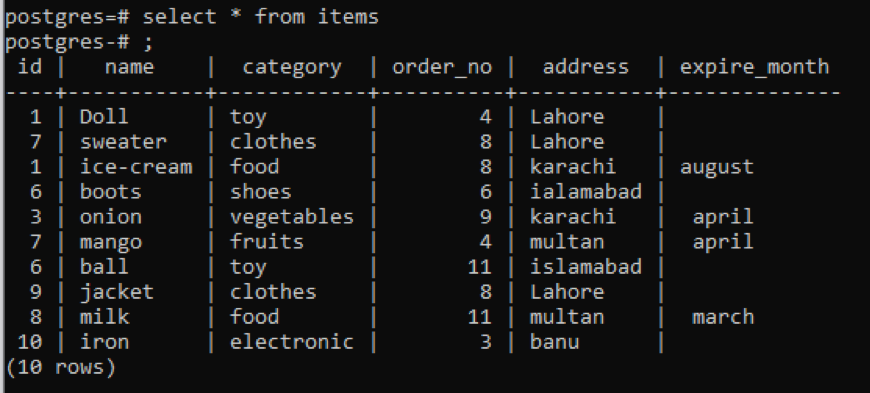
Независимо от того, отображается ли вся информация о таблице, если вы хотите ограничить представление и хотите, чтобы отображались только описание столбца и тип данных конкретной таблицы, это часть общедоступной схемы. Мы упоминаем имя таблицы в команде, из которой мы хотим отображать данные.
>> select table_name, column_name, data_type from information_schema.columns where table_name =’passenger’;

На изображении ниже table_name и column_names упоминаются с типом данных перед каждым столбцом, поскольку целое число является постоянным типом данных и не имеет ограничений, поэтому для него не нужно использовать ключевое слово «изменяющийся».

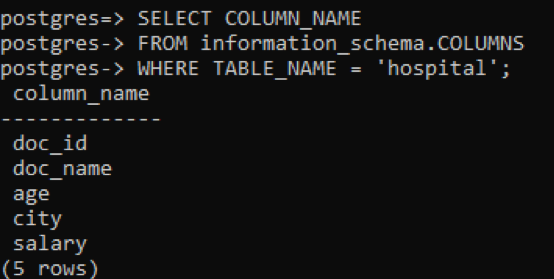
Чтобы сделать его более точным, мы также можем использовать только имя столбца в команде, чтобы отображать только имена столбцов таблицы. Рассмотрим для этого примера таблицу «Больница».
>> select column_name from information_schema.columns where table_name = ‘hospital’;
Если мы используем «*» в той же команде для выборки всех записей таблицы, присутствующих в схеме, мы столкнемся с большим объемом данных, потому что все данные, включая конкретные данные, отображаются в таблице.
>> select * from information_schema columns where table_name = ‘technology’;

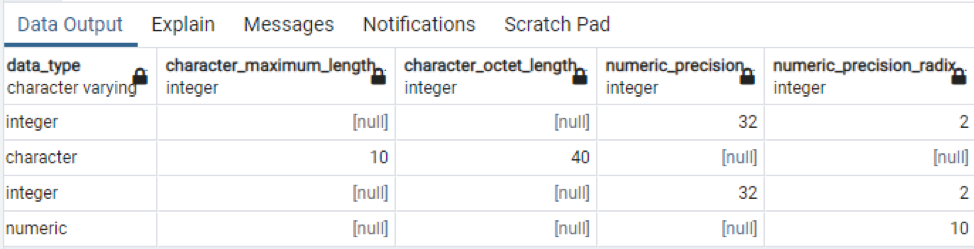
Это часть имеющихся данных, так как невозможно отобразить все результирующие значения, поэтому мы сделали несколько снимков некоторых данных, чтобы создать небольшое представление.
Чтобы увидеть количество всех таблиц в схеме базы данных, мы используем команду для просмотра описания.
>> select * from information_schema.tables;

Выходные данные показывают имя схемы, а также тип таблицы вместе с таблицей.
Как и вся информация в конкретной таблице. Если вы хотите отобразить все имена столбцов таблиц, представленных в схеме, мы применяем команду, добавленную ниже.
>> select * from information_schema.columns;

Выходные данные показывают, что есть тысячи строк, которые отображаются в качестве результирующего значения. Это показывает имя таблицы, владельца столбца, имена столбцов и очень интересный столбец, который показывает положение/расположение столбца в своей таблице, где он был создан.

Заключение
Эта статья объясняет «Как описать таблицу в PostgreSQL», включая базовую терминологию в команде. Описание включает имя столбца, тип данных и схему таблицы. Расположение столбца в любой таблице — это уникальная особенность postgresql, которая отличает ее от других систем управления базами данных.
Редактор: AndreyEx




