В быстро меняющемся мире современных коммуникаций компьютерные сети играют незаменимую роль в облегчении обмена информацией на огромных расстояниях. Будь то отправка электронной почты, потоковое видео или доступ к веб-сайту, бесперебойная передача данных имеет решающее значение. Однако в условиях цифрового безумия ошибки могут проникать в процесс передачи, потенциально приводя к повреждению или потере данных. Именно здесь на помощь приходят механизмы обнаружения ошибок, обеспечивающие целостность и надежность данных, передаваемых по компьютерным сетям.
Как возникают ошибки при передаче данных?
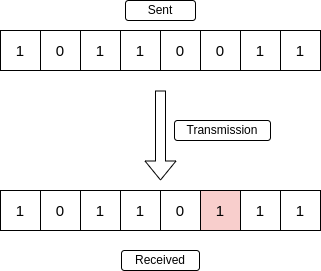
Ошибки при передаче данных могут возникать по целому ряду причин, таких как электромагнитные помехи, шум, неисправное оборудование или даже программные сбои. Эти ошибки могут приводить к изменению, вставке, удалению или инверсии битов в передаваемых данных, тем самым ставя под угрозу точность и аутентичность информации. Учитывая критический характер многих сетевых приложений, крайне важно использовать методы обнаружения ошибок для выявления и исправления этих ошибок.
Типы ошибок
В контексте компьютерных сетей и передачи данных ошибки могут возникать из-за различных факторов, приводящих к повреждению или потере данных. Эти ошибки можно разделить на различные типы в зависимости от их происхождения и характеристик. Вот некоторые из наиболее распространенных типов ошибок в компьютерных сетях:
1. Однобитовая ошибка: Однобитовая ошибка возникает, когда один бит в блоке данных изменяется с 0 на 1 или с 1 на 0 из-за шума, помех или других факторов. Однобитовые ошибки относительно распространены и обычно могут быть обнаружены и исправлены с помощью методов обнаружения ошибок, таких как проверка на четность или коды Хэмминга.

2. Пакетная ошибка: Пакетная ошибка включает последовательное изменение нескольких битов в блоке данных. Эти ошибки могут возникать из-за таких факторов, как ослабление сигнала, электрические помехи или проблемы с синхронизацией. Пакетные ошибки могут быть более сложными для обнаружения и исправления, чем однобитовые ошибки, особенно если они превышают возможности используемого механизма обнаружения ошибок.

3. Случайные (переходные) Ошибки: Случайные ошибки — это временные и непредсказуемые изменения в данных, вызванные такими факторами, как временные электрические помехи, космические лучи или кратковременные сбои. Эти ошибки, как правило, недолговечны и не всегда могут быть обнаружены, в зависимости от используемого механизма обнаружения ошибок.
4. Систематическая ошибка: Систематические ошибки, также известные как детерминированные ошибки, представляют собой последовательные и повторяемые ошибки, возникающие из-за недостатков в системе или оборудовании. Эти ошибки могут возникать из-за неисправных аппаратных компонентов, неправильных настроек или программных ошибок. Систематические ошибки могут оказывать значительное влияние на целостность данных и могут потребовать тщательного устранения неполадок и исправления.
5. Шум: шум относится к любому нежелательному сигналу или помехе, которые искажают исходные данные. Шум может возникать во время передачи данных из-за различных источников, таких как электромагнитные помехи, перекрестные помехи или ослабление канала. Хотя шум не всегда может приводить к явным ошибкам, он может ухудшить качество передаваемых данных и повлиять на общую надежность связи.
Важность обнаружения ошибок
Обнаружение ошибок имеет первостепенное значение в компьютерных сетях, поскольку оно помогает поддерживать целостность данных и гарантирует, что полученная информация является точным представлением того, что было отправлено. Без надлежащих механизмов обнаружения ошибок повреждение данных может привести к серьезным последствиям, включая финансовые потери, нарушение безопасности и ухудшение качества работы пользователей. Внедряя эффективные методы обнаружения ошибок, сетевые администраторы могут минимизировать эти риски и повысить общую надежность своих систем.
Различные типы методов обнаружения ошибок
Для защиты данных во время передачи было разработано и стандартизировано несколько методов обнаружения ошибок. Вот несколько известных из них:
1. Проверка четности: биты четности добавляются к данным, чтобы общее количество единиц было четным или нечетным, что позволяет обнаруживать однобитовые ошибки. Несмотря на простоту реализации, проверки на четность ограничены в своей способности обнаруживать множество ошибок.

2. Контрольные суммы: Контрольные суммы включают вычисление суммы или хэш-значения из битов данных и добавление его к передаваемым данным. Получатель выполняет те же вычисления и сравнивает результаты. Любое несоответствие указывает на ошибку.

3. Проверка циклической избыточности (CRC): CRC — это широко используемый метод обнаружения ошибок, который включает полиномиальное деление. Отправитель и получатель используют один и тот же многочлен для выполнения деления, и любой остаток указывает на наличие ошибок.


4. Код Хэмминга: коды Хэмминга вносят избыточность, добавляя дополнительные биты к данным. Эти биты расположены таким образом, что позволяют приемнику обнаруживать и исправлять однобитовые ошибки и определенные типы многобитовых ошибок.
Передовые методы и исправление ошибок
Хотя методы обнаружения ошибок полезны для выявления ошибок, методы исправления ошибок делают процесс еще более сложным, не только обнаруживая ошибки, но и исправляя их. Такие методы, как коды Рида-Соломона и турбокоды, способны не только выявлять ошибки, но и восстанавливать утерянные или поврежденные данные с помощью передовых математических алгоритмов.
Заключение
В сфере компьютерных сетей, где надежность передачи данных имеет первостепенное значение, методы обнаружения ошибок стоят на страже целостности данных. Внедряя эти методы, сетевые администраторы могут гарантировать, что информация, которой обмениваются устройства и системы, остается точной и неповрежденной. От простых проверок на четность до сложных проверок циклического резервирования и усовершенствованных кодов исправления ошибок — набор методов обнаружения ошибок продолжает развиваться в соответствии с требованиями все более взаимосвязанного мира. В стремлении к бесперебойной связи и обмену информацией обнаружение ошибок остается важной основой проектирования и эксплуатации сети.
Часто задаваемые вопросы (FAQs)
Вот некоторые из часто задаваемых вопросов по обнаружению ошибок в компьютерных сетях.
1. Какова цель обнаружения ошибок в компьютерных сетях?
Ответ: Обнаружение ошибок в компьютерных сетях служит для обеспечения целостности и надежности передачи данных. Оно включает в себя внедрение методов для выявления ошибок, таких как переключение битов или повреждение, которые могут возникать во время передачи данных. Обнаруживая эти ошибки, сети могут предпринимать корректирующие действия, такие как запрос на повторную передачу поврежденных данных, тем самым предотвращая повреждение данных и поддерживая точность передаваемой информации.
2. Как работает алгоритм циклической проверки избыточности (CRC)?
Ответ: Алгоритм циклической проверки избыточности (CRC) — это метод обнаружения ошибок, который включает деление на полиномы. Отправитель генерирует контрольную сумму (остаток) на основе данных, которые должны быть переданы, используя заранее определенный полином. Эта контрольная сумма добавляется к данным перед передачей. На стороне получателя выполняется такое же полиномиальное деление принятых данных, и если вычисленная контрольная сумма совпадает с полученной контрольной суммой, предполагается, что данные не содержат ошибок. При наличии несоответствия обнаруживается ошибка, вызывающая необходимость повторной передачи данных.
3. Какую роль биты четности играют в обнаружении ошибок?
Ответ: Биты четности — это основная форма обнаружения ошибок, используемая в компьютерных сетях. Бит четности добавляется к блоку данных, чтобы гарантировать, что общее количество единиц в блоке (включая бит четности) является четным или нечетным. Если получатель считает единицы и обнаруживает несоответствие ожидаемой четности, обнаруживается однобитовая ошибка. Хотя проверки на четность просты в реализации и могут обнаруживать однобитовые ошибки, им не хватает возможности идентифицировать и исправлять более сложные ошибки.
4. Как коды Хэмминга улучшают обнаружение и исправление ошибок?
Ответ: Коды Хэмминга — это тип кода для исправления ошибок, который добавляет избыточные биты к данным, чтобы обеспечить обнаружение и исправление однобитовых ошибок. Эти коды используют определенное расположение битов для обеспечения возможностей обнаружения и исправления ошибок. Добавляя тщательно расположенные биты четности, коды Хэмминга позволяют получателю точно определить местоположение ошибки и исправить ее. Это делает их более эффективными, чем простые проверки четности, для обнаружения и исправления ошибок при передаче данных.
5. Каково значение джиттера в сетевой коммуникации?
Ответ: Дрожание относится к изменению времени прибытия пакета данных к получателю в компьютерной сети. Оно вызвано, среди прочего, перегрузкой сети, различными задержками передачи и изменениями маршрута. Дрожание особенно важно в приложениях реального времени, таких как потоковая передача голоса и видео, где последовательная и предсказуемая доставка пакетов необходима для поддержания бесперебойной связи. Чрезмерное дрожание может привести к сбоям, задержкам и снижению качества в этих приложениях, влияя на работу пользователей. Сетевые администраторы должны управлять дрожанием, чтобы обеспечить оптимальную производительность в сценариях обмена данными в режиме реального времени.