Высокая частота переключения контекста и прерываний: как диагностировать и исправить в Linux
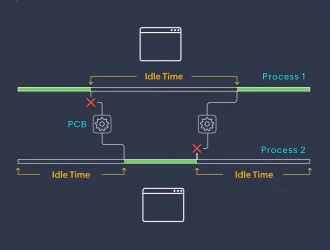
Как несколько процессов, таких как видеоплееры или Google Chrome, могут выполняться одновременно на одном компьютере с одним ядром? Ответ заключается в механизме, называемом переключением контекста, который позволяет операционной системе выполнять многозадачность и позволяет нескольким процессам совместно использовать один процессор.
Однако переключение контекста может повлиять на производительность системы. Чтобы диагностировать и устранить высокую частоту переключения контекста и прерываний в Linux, мы должны сначала понять эти термины и то, как они могут повлиять на вашу систему.
Что такое переключение контекста?
Переключение контекста — это процесс сохранения текущего состояния центрального процессора в блоке управления процессом (структура данных, управляемая Linux) для задачи, над которой он работает, чтобы это сохраненное состояние можно было перезагружать каждый раз, когда эта задача возобновляется. Переключение контекста позволяет нескольким процессам совместно использовать один процессор и, как таковое, является частью основных функциональных возможностей многозадачной операционной системы.
Какова частота прерываний?
Частота прерываний — это количество прерываний, происходящих с течением времени на сервере Linux. Чем выше частота прерываний, тем сильнее ее влияние на производительность системы.
Проверка частоты переключения контекста и прерываний в вашей системе
Может быть трудно определить, связано ли высокое переключение контекста и частота прерываний с проблемами вашего производственного сервера, отчасти из-за огромного количества других потенциальных виновников. К счастью, у нас есть несколько инструментов, которые мы можем использовать для проверки количества переключений контекста и частоты прерываний в Linux: vmstat, pidstat, и perf.
vmstat
Давайте начнем с vmstat, встроенного инструмента командной строки, который собирает информацию о памяти, системных процессах, подкачке, прерываниях, вводе-выводе или планировании процессора. Например, мы можем использовать его для проверки показателей мониторинга нашей системы с интервалом в 5 секунд и фиксированием только 10 раз:
vmstat 5 10

Рис. 1: vmstat результаты для интервала 5 секунд и 10 раз
Здесь объем памяти данных указан в килобайтах (КБ), а загрузка ЦП указана в процентах.
В качестве альтернативы, если мы хотим отобразить активную и неактивную память нашей системы в мегабайтах, мы можем использовать
vmstat -a -S m

Рис. 2: vmstat показывает активную и неактивную память в мегабайтах
pidstat
Системные администраторы часто используют pidstat инструмент для мониторинга задач, которыми в настоящее время управляет ядро Linux.
Например, чтобы показать все задачи, мы можем запустить
pidstat
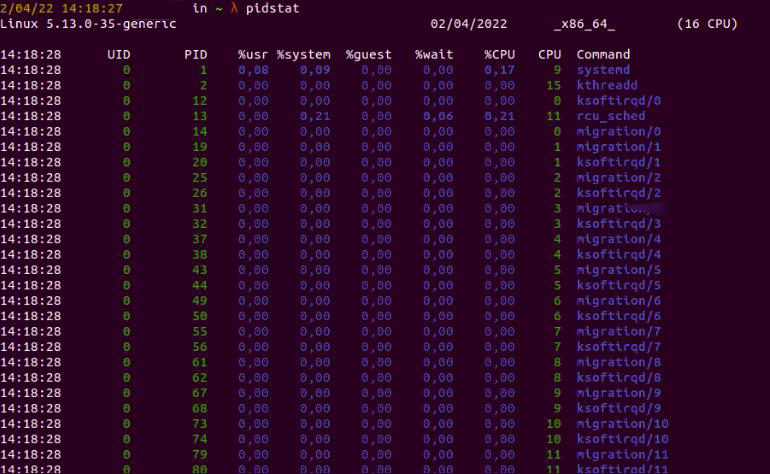
Рис. 3: Результаты для команды pidstat
Если мы хотим отобразить только статистику процесса базы данных Postgres, мы можем запустить
pidstat -C "${process-name}"
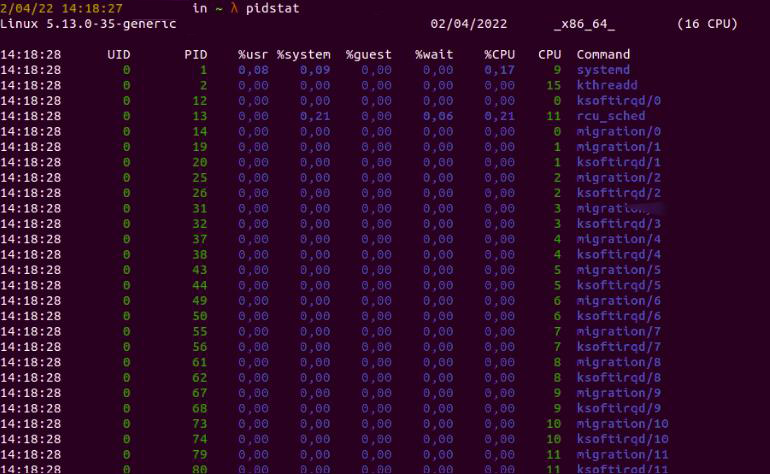
Рис. 4: pidstat отображение процесса Postgres
В качестве альтернативы мы могли бы захотеть получить статистику о процессе по его идентификатору:
pidstat -p ${process-id}

Рис. 5: pidstat показывает статистику по определенному идентификатору процесса
cperf
Команда perf отображает комбинации счетчиков производительности, таких как показатели производительности. Кроме того, она может внедрять в ядро небольшие скрипты для обработки этих данных в режиме реального времени.
Для установки perf, нам сначала необходимо установить инструменты Linux.
sudo apt-get install linux-tools-common linux-tools-generic linux-tools-`uname -r
Затем мы можем получить статистику счетчика для всей системы за пять секунд, используя команду perf.
sudo perf stat -a sleep 5
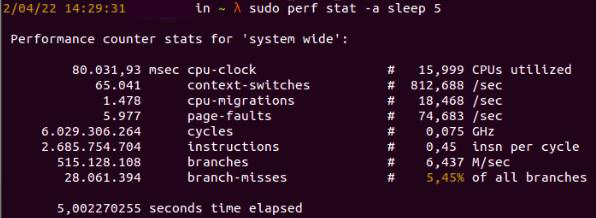
Рис. 6: Команда perf показывает статистику в течение 5 секунд
Мы также можем профилировать определенный процесс по его идентификатору в течение 10 секунд при частоте 99 Герц. Выборка с более высокой частотой (например, 999 или 9999) приведет к большим накладным расходам. Кроме того, выборка с нечетной частотой (например, 99 вместо 100) предотвратит проблемы с дискретизацией с фиксированным шагом (профилирование выборок с одинаковой частотой и получение неправильных результатов выборки).
sudo perf record -F 99 -p PID sleep 10

Рис. 7: perf показывает данные, отфильтрованные по частоте
Устранение неполадок с переключением высокого контекста
Для более подробной демонстрации мы будем использовать фиктивное приложение на языке программирования Go, у которого проблема с высокой частотой переключения контекста.
Приложение будет считывать данные из csv-файла. CSV-файл содержит данные для даты и времени past_date и future_date,, например, «2006-12-28” и “2030-03-23”.
Вот содержание time.csv как показано ниже:
past_date, future_date 2007-05-24, 2022-02-07 2004-07-23, 2021-03-02 2003-03-24, 2034-04-02 2008-03-25, 2021-02-04 2001-11-26, 2032-05-12 2008-09-21, 2022-03-22 2007-10-28, 2031-07-12 2009-03-25, 2052-02-20
Код приложения реализован следующим образом:
package main
import (
"encoding/csv"
"fmt"
"log"
"os"
"sync"
"time"
)
func f(from string) {
var wg sync.WaitGroup
sliceLength := 1000000
wg.Add(sliceLength)
for i := 0; i < sliceLength; i++ {
records := readCsvFile("time.csv")
go func(i int) {
defer wg.Done()
for _, record := range records {
layout := "2006-01-02"
past_date, _ := time.Parse(layout, record[0])
future_date, _ := time.Parse(layout, record[1])
past_date.Date()
future_date.Date()
}
}(i)
}
wg.Wait()
}
func readCsvFile(filePath string) [][]string {
f, err := os.Open(filePath)
if err != nil {
log.Fatal("Не удается прочитать входной файл "+filePath, err)
}
defer f.Close()
csvReader := csv.NewReader(f)
records, err := csvReader.ReadAll()
if err != nil {
log.Fatal("Не удается разобрать файл в формате CSV для "+filePath, err)
}
return records
}
func main() {
f("direct")
fmt.Println("сделано")
}
Прежде чем мы проверим проблемы с производительностью в нашем приложении, мы должны сначала закрыть все запущенные процессы на сервере, которые нам не нужны, чтобы процесс мониторинга производительности был более эффективным.
Чтобы запустить приложение, мы начнем с выполнения этой команды:
go run main.go
Далее мы проверим частоту переключения контекста, выполнив vmstat. (Поскольку vmstat — это облегченная команда, мы можем быть уверены, что ее выполнение не повлияет на мониторинг производительности.)
vmstat 1

Рис. 8: vmstat, показывающий показатели мониторинга производительности
На рисунке 8 у нас есть различные заголовки столбцов, такие как cs, us, sy, id, wa и st. Они обозначают количество системных прерываний (in), переключений контекста (cs), процент процессорного времени на неядерных процессах (us), процент процессорного времени на процессах ядра (sy), процент времени простоя процессора (id), процент времени, затраченного на ожидание ввода/вывода (wa), и процент времени, украденного виртуальной машиной (st).
Мы рассматриваем 201 516 переключений контекста, а частота прерываний составляет 65 259. Эти необычные цифры указывают на связанную с этим проблему с производительностью в нашем приложении.
Определение основной причины
Если мы внимательнее посмотрим на наш код, то увидим, что мы используем goroutine для ускорения работы приложения. Однако из-за специфики приложения — оно извлекает данные только из небольшого csv-файла — нам не нужно использовать подход параллелизма с goroutines. Фактически, этот подход параллелизма является основной причиной нашей высокой частоты переключения контекста.
При повторении цикла for в goroutine основная goroutine должна будет проверять наличие существующих итераторов в других подпрограммах, так что мы выполняем цикл только 1 000 000 раз.
for i := 0; i < sliceLength; i++ {
records := readCsvFile("time.csv")
go func(i int) {
defer wg.Done()
for _, record := range records {
layout := "2006-01-02"
past_date, _ := time.Parse(layout, record[0])
future_date, _ := time.Parse(layout, record[1])
past_date.Date()
future_date.Date()
}
}(i)
}
wg.Wait()
}
В результате основной подпрограмме потребуется постоянно проверять разные подпрограммы, и это приведет к увеличению числа переключений контекста.
Устранение проблем с высокой скоростью переключения контекста
Эту проблему можно решить, удалив подпрограммы. Вместо использования нескольких подпрограмм мы будем выполнять цикл только в одной основной подпрограмме.
package main
import (
"encoding/csv"
"fmt"
"log"
"os"
"time"
)
func f(from string) {
sliceLength := 1000000
for i := 0; i < sliceLength; i++ {
records := readCsvFile("time.csv")
for _, record := range records {
layout := "2006-01-02"
past_date, _ := time.Parse(layout,record[0])
future_date, _ := time.Parse(layout,record[1])
past_date.Date()
future_date.Date()
}
}
}
func readCsvFile(filePath string) [][]string {
f, err := os.Open(filePath)
if err != nil {
log.Fatal("Не удается прочитать входной файл "+filePath, err)
}
defer f.Close()
csvReader := csv.NewReader(f)
records, err := csvReader.ReadAll()
if err != nil {
log.Fatal("Не удается разобрать файл в формате CSV для "+filePath, err)
}
return records
}
func main() {
f("direct")
fmt.Println("сделано")
}
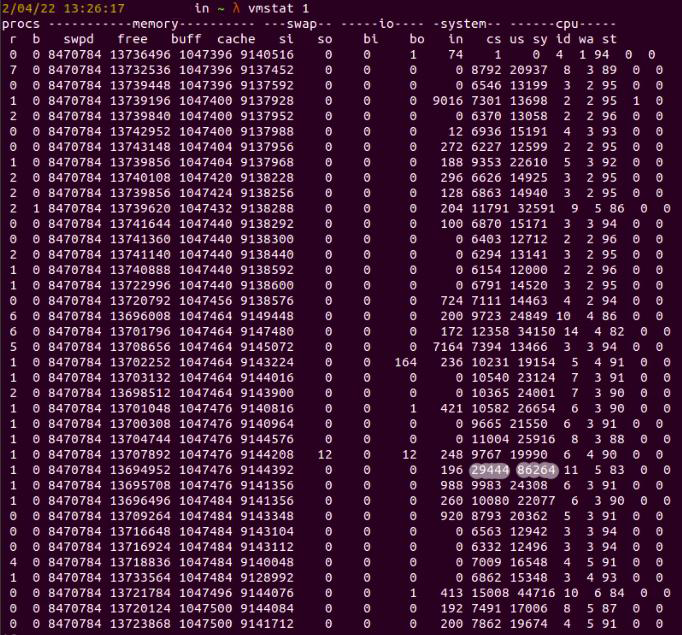
Рис. 9: Переключение контекста теперь сокращено
Заключение
Может быть много причин высокой частоты переключения контекста и прерываний в Linux. Независимо от основной причины, повышенное переключение контекста является верным признаком того, что у нашей системы проблемы с производительностью, которые мы должны немедленно обновить.
Поначалу это может оказаться непростой задачей, поскольку требует знаний о том, как работает сервер Linux, а также о том, как реализованы приложения в Linux. Теперь, когда вы понимаете, что такое высокая частота переключения контекста и прерываний на серверах Linux, и после изучения шагов, которые необходимо предпринять для устранения проблемы, вы сможете с уверенностью устранять неполадки.
Редактор: AndreyEx




