Мониторинг производительности сервера Linux
Системные администраторы часто получают жалобы, связанные с низкой производительностью сервера, и устранить эти проблемы может быть сложно, поскольку они носят субъективный характер. Медленная работа сервера конечным пользователем может быть вызвана запущенным процессом, потребляющим больше ресурсов, чем обычно, или на самом деле что-то не так с сервером.
Какой бы ни была причина, важно регулярно отслеживать производительность сервера, чтобы:
- Обеспечение бесперебойного и безошибочного функционирования сервера
- Понимание использования ресурсов серверной системы
- Выявляйте проблемы до того, как они повлияют на конечных пользователей, даже на небольшое количество пользователей
- Получите представление об отзывчивости и доступности сервера
- Выявление процессов, которые внезапно начали потреблять больше ресурсов, чем обычно, что может привести к перегрузке сервера
- Выявление угроз безопасности
В этой статье мы обсудим различные показатели, используемые для мониторинга производительности сервера и устранения проблем с производительностью.
Показатели производительности сервера
Несколько показателей могут помочь отслеживать три основных компонента любого сервера — процессор, оперативную память и операции ввода—вывода с диска — чтобы получить представление о том, как работает ваш сервер Linux. Некоторые из этих показателей:
- Загрузка процессора: процентное соотношение времени процессора для выполнения задачи
- Средняя нагрузка: Количество процессов, запущенных на процессоре за некоторое время
- Время безотказной работы: Количество времени, прошедшего с момента последней перезагрузки системы
- Использование памяти: Процент использования памяти
- Загрузка диска: Процент от общего используемого дискового пространства
- Время ожидания ввода-вывода: Процент времени процессора, затраченного на ожидание операций ввода-вывода.
Последствия низкой производительности сервера Linux
Различные проблемы с производительностью возникают в разных операционных системах или службах, и каждая проблема требует уникального подхода к устранению неполадок. Большинство проблем вызвано работой процессора, диска, памяти, сети и ввода-вывода.
Каждая область выдает разные симптомы и требует другой диагностики и решения для снижения медлительности сервера.
Например, если сервер работает медленно или устарел, система не сможет соответствовать требованиям современных приложений. Это может привести к тому, что конечные пользователи столкнутся с увеличением времени отклика, что вызовет у них разочарование и снизит их доверие к вашему приложению.
Запросы к базе данных также могут занимать слишком много времени для извлечения данных, что приводит к снижению производительности приложений. Медленный сервер также может напрямую повлиять на возможности использования центрального процессора.
Наконец, низкая производительность сервера иногда может приводить к простоям, хотя вероятность такого возникновения невелика.
Причины медленной работы серверов Linux
Чрезмерная загрузка системы, вероятно, является одной из наиболее распространенных причин замедления работы системы.
Загрузка системы с ограниченным процессором может создавать проблемы из-за процессов, ожидающих ресурсов процессора, в то время как загрузка системы с ограниченным объемом оперативной памяти может привести к увеличению времени ожидания ввода-вывода, поскольку система начинает использовать подкачку на сервере, когда у него заканчивается оперативная память. Между тем, загрузка системы, ограниченная вводом-выводом, может привести к замедлению, поскольку процессы конкурируют за ресурсы дискового или сетевого ввода-вывода. Большое время работы пользователя ЦП также может способствовать высокой загрузке системы.
Дополнительные факторы, которые могут привести к замедлению работы сервера, включают:
- Ненужные службы запускаются во время загрузки
- Ненормальные объемы памяти из-за того, что несколько интенсивно используемых сервисов остались открытыми
- Сбой при обновлении операционной системы (OS) и программного обеспечения
- Обнаруженные и необнаруженные вирусы
- Узкие места в сети, чрезмерный сетевой трафик и трафик базы данных
Устранение неполадок в производительности сервера Linux
Linux предлагает различные команды для устранения неполадок в производительности системы. Эти команды помогают контролировать различные компоненты вашей системы, такие как память, центральный процессор и ввод-вывод. Тремя наиболее часто используемыми командами являются команды top, vmstat, и iostat.
Команда top
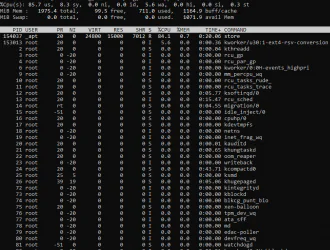
Команда top является наиболее часто используемой командой для отображения общего вида системы. В нем суммируются различные показатели уровня процессора, рассмотренные в вышеприведенных разделах, включая время безотказной работы, средние значения нагрузки и время ожидания ввода-вывода. Кроме того, он отображает запущенный список процессов или задач, которыми в данный момент управляет ядро.
Синтаксис:
top [options]
Пример:
При запуске команды top отобразится результат, аналогичный показанному ниже:
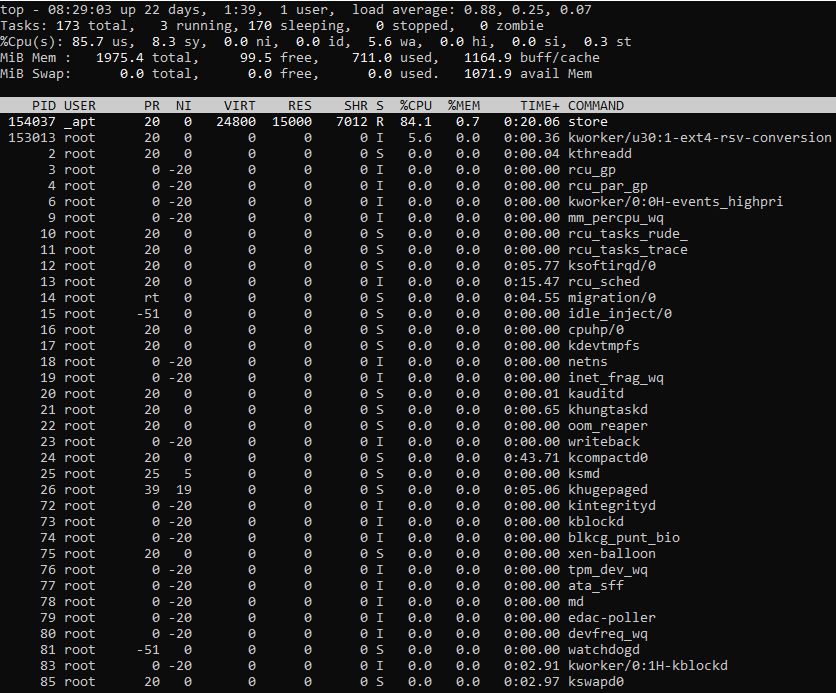
Рис. 1: Вывод команды top
Как вы можете видеть в приведенных выше выходных данных, в первом разделе отображается сводная информация о системе в реальном времени и динамике.
В первой строке отображается время безотказной работы вместе со средними значениями загрузки системы за последние один, пять и 15-минутный периоды. Если среднее значение нагрузки превышает нормальное значение нагрузки, т.е. 0,7 с интервалом в одну и пять минут, его можно игнорировать. Когда среднее значение нагрузки остается стабильно выше 0,7 в течение более длительного времени, это явный признак того, что сервер перегружен.
Во второй строке отображается различная информация на уровне задач, включая активные, запущенные и спящие задачи.
В третьей строке с надписью %CPU(s), отображаются различные статистические данные на уровне процессора. Вот некоторые показатели для мониторинга::
- us: Процентное соотношение процессорного времени для пользовательских процессов
- sy: Процентное соотношение времени процессора для системных процессов
- id: Процент времени процессора, проведенного в режиме ожидания
- wa: Процент процессорного времени, затраченного на ожидание завершения операций ввода-вывода
В четвертой и пятой строках отображаются данные о системной памяти, в то время как в последнем разделе отображается динамический список процессов в режиме реального времени. Вы можете отсортировать этот список на основе различных показанных столбцов. Например, нажатие P приведет к сортировке процессов на основе столбца %CPU.
Команда vmstat
Следующая важная команда в списке — команда vmstat, которая расшифровывается как статистика виртуальной памяти. Это инструмент мониторинга производительности, предоставляемый Linux, который отображает различную статистику о различных компонентах системы, включая память, ввод-вывод и центральный процессор.
По умолчанию эта команда отображает отчеты с момента последней перезагрузки системы. Однако вы также можете просматривать статистику в реальном времени, которая обновляется через указанный вами интервал.
Синтаксис:
vmstat [options][delay [count]]
Для просмотра отчетов в режиме реального времени можно использовать следующие два параметра:
- delay : Для непрерывного обновления отчетов после указанной задержки в секундах
- count: Для определения количества требуемых обновлений; значение по умолчанию бесконечно
Пример:
Выполнение команды vmstat выдаст вам результат, аналогичный следующему:

Рис. 2: Вывод команды vmstat
Выходные данные разделены на пять разделов.
- В memory разделе отображается следующая информация:
- swpd: Общий объем памяти, используемой в качестве виртуальной
- free: Доступно общее количество свободной/незанятой памяти (в килобайтах)
- buff: память временно используется в качестве буфера данных
- cache: Общая кэш-память
- В swap разделе отображается следующая информация:
- si: Объем памяти (в килобайтах), заменяемый с диска в секунду
- so: объем памяти (в килобайтах), заменяемый на диск в секунду
- В io разделе отображается следующая информация:
- bi: количество блоков, получаемых от блочного устройства в секунду
- bo: Количество блоков, отправляемых на блочное устройство в секунду
- В system разделе отображается следующая информация:
- in: Количество прерываний в секунду, включая тактовые, с момента последней загрузки системы
- cs: Количество переключений контекста в секунду, когда ядро переключается с обработки в системном режиме на обработку в пользовательском режиме
В cpu разделе отображаются данные, аналогичные тем, которые содержатся в строке %Cpu(s) в выводе верхней команды.
Команда iostat
Команда iostat это важная и широко используемая команда для мониторинга статистики ввода/вывода вашей системы. Хотя такие команды, как top или vmstat, могут помочь вам обнаружить, что сервер испытывает большое время ожидания ввода-вывода, вы также должны знать, какие устройства/разделы находятся под нагрузкой и вызывают большое время ожидания ввода-вывода.
Команда iostat выполняет именно это и генерирует отчеты на уровне устройства. Кроме того, она также выдает статистику на уровне процессора, аналогичную тем, которые предоставляются командами top и vmstat. Точно так же, как vmstat, выводимые данные по умолчанию относятся к времени, прошедшему с момента последней перезагрузки системы, но вы можете просматривать данные в режиме реального времени, указав пару дополнительных параметров.
Синтаксис:
iostat [option] [interval] [count]
Параметры interval и count здесь аналогичны параметрам в команде vmstat и используются для отображения обновлений в реальном времени бесконечно или для определенных значений.
Пример:
Выполнение команды iostat выдаст вам результат, аналогичный показанному ниже:
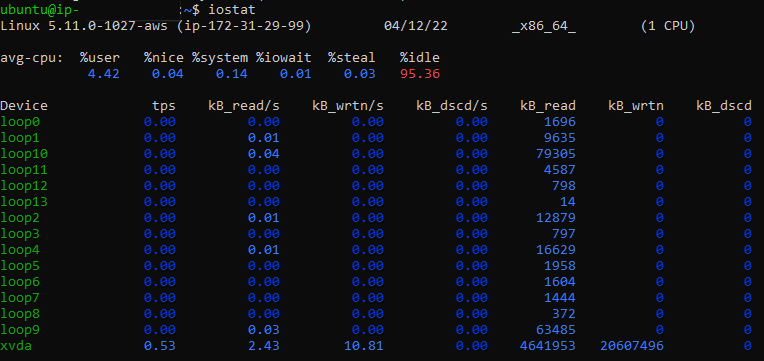
Рис. 3: Вывод команды iostat
Как вы можете видеть в приведенном выше выводе, в первой строке отображается отчет процессора:
- % user: Произошла загрузка ЦП при выполнении на уровне пользователя
- % nice: Загрузка ЦП произошла при выполнении на уровне пользователя с хорошим приоритетом
- % system: Загрузка ЦП произошла во время выполнения на системном уровне (ядро)
- % iowait: процент времени, которое центральный процессор проводил в режиме ожидания, пока система ожидала завершения запроса ввода-вывода
- %steal: процент времени, затраченного процессором на ожидание, пока гипервизор обслуживал другой виртуальный процессор
- % idle: процент времени, проведенного процессором в режиме ожидания, а также отсутствие невыполненных запросов ввода-вывода
В следующем разделе приведена следующая статистика для всех устройств/разделов в системе:
- Device: Название раздела/устройства
- tps: передача данных в секунду — более высокая скорость передачи данных свидетельствует о загруженности процессора и может повлиять на производительность сервера
- Blk_read/s (kB_read/s): количество блоков данных в килобайтах, считываемых с устройства в секунду
- Blk_wrtn/s (kB_wrtn/s): количество блоков данных в килобайтах, записываемых на устройство в секунду
- Blk_read (kB_read): Общее количество блоков в килобайтах, прочитанных с этого устройства с момента последней перезагрузки
- Blk_wrtn (kB_wrtn): Общее количество блоков в килобайтах, записанных на это устройство с момента последней перезагрузки
- Blk_dscd (kB_dscd): Общее количество блоков в килобайтах, сброшенных для этого устройства с момента последней перезагрузки
- Blk_dscd/s (kB_dscd): Общее количество блоков в килобайтах, отбрасываемых для этого устройства в секунду
Следует исследовать очень высокие значения Blk_wrtn/s или Blk_read/s для конкретного устройства или раздела, поскольку это может увеличивать нагрузку на центральный процессор и, следовательно, снижать производительность сервера.
Заключение
Производительность сервера имеет решающее значение, поскольку она может напрямую повлиять на базу пользователей приложения. Мониторинг показателей производительности помогает выявить и устранить любые проблемы на сервере до того, как это может повлиять на ваше приложение.
В этой статье мы упомянули основные команды — top, vmstat, и iostat—that, которые можно использовать для определения причин замедления работы системы. Описанные здесь методы можно использовать для устранения неполадок и устранения проблем с постоянством.
Редактор: AndreyEx




