Как установить и настроить Apache Hadoop в Ubuntu

Apache Hadoop — это свободно доступная программная платформа на основе Java с открытым исходным кодом для хранения и анализа больших наборов данных в ваших системных кластерах. Он хранит свои данные в распределенной файловой системе Hadoop (HDFS) и обрабатывает их с помощью MapReduce. Hadoop использовался в методах машинного обучения и интеллектуального анализа данных. Он также используется для управления несколькими выделенными серверами.
Основными компонентами Apache Hadoop являются:
- HDFS : в Apache Hadoop HDFS — это файловая система, распределенная по многочисленным узлам.
- MapReduce : это платформа для разработки приложений, обрабатывающих большие объемы данных.
- Hadoop Common : это набор библиотек и утилит, необходимых для модулей Hadoop.
- Hadoop YARN : в Hadoop Hadoop Yarn управляет слоями ресурсов.
Теперь ознакомьтесь с приведенными ниже методами установки и настройки Apache Hadoop в вашей системе Ubuntu. Итак, начнем!
Как установить Apache Hadoop в Ubuntu
Прежде всего, мы откроем наш терминал Ubuntu, нажав «CTRL + ALT + T», вы также можете ввести «терминал» в строке поиска приложений.
Следующим шагом будет обновление системных репозиториев:
$ sudo apt update
Теперь мы установим Java в нашу систему Ubuntu, выполнив следующую команду в терминале:
$ sudo apt install openjdk-11-jdk
Введите «y/Y», чтобы продолжить процесс установки.
Теперь проверьте наличие установленной Java, проверив ее версию:
$ java -version
Мы создадим отдельного пользователя для запуска Apache Hadoop в нашей системе с помощью команды adduser :
$ sudo adduser hadoopuser
Введите пароль нового пользователя, его полное имя и другую информацию. Введите «y/Y», чтобы подтвердить правильность предоставленной информации.
Пришло время переключить текущего пользователя на созданного пользователя Hadoop, которым в нашем случае является «hadoopuser»:
$ su - hadoopuser
Теперь используйте приведенную ниже команду для создания пар закрытого и открытого ключей:
$ ssh-keygen -t rsa
Введите адрес файла, в котором вы хотите сохранить пару ключей. После этого добавьте парольную фразу, которую вы собираетесь использовать во всей настройке пользователя Hadoop.
Затем добавьте эти пары ключей в ssh authorized_keys:
at ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
Поскольку мы сохранили сгенерированную пару ключей в авторизованном ключе ssh, теперь мы изменим права доступа к файлу на «640», что означает, что только мы, как «владелец» файла, будем иметь права на чтение и запись, у групп есть только разрешение на чтение. Никакие разрешения не будут предоставлены «другим пользователям»:
$ chmod 640 ~/.ssh/authorized_keys
Теперь аутентифицируйте локальный хост, выполнив следующую команду:
$ ssh localhost
Используйте приведенную ниже команду wget для установки фреймворка Hadoop в вашей системе:
Распакуйте загруженный файл «hadoop-3.3.0.tar.gz» с помощью команды tar:
$ tar -xvzf hadoop-3.3.0.tar.gz
Вы также можете переименовать извлеченный каталог, как мы это сделаем, выполнив приведенную ниже команду:
$ mv hadoop-3.3.0 hadoop
Теперь настройте переменные среды Java для настройки Hadoop. Для этого мы проверим расположение нашей переменной «JAVA_HOME»:
$ dirname $(dirname $(readlink -f $(which java)))
Откройте файл «~/.bashrc» в любимом текстовом редакторе, например nano:
$ nano ~/.bashrc
Добавьте следующие пути в открытый файл «~/.bashrc»:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 export HADOOP_HOME=/home/hadoopuser/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export HADOOP_YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
После этого нажмите «CTRL + O», чтобы сохранить изменения, внесенные в файл.
Теперь напишите приведенную ниже команду, чтобы активировать переменную среды «JAVA_HOME»:
$ source ~/.bashrc
Следующее, что нам нужно сделать, это открыть файл переменных среды Hadoop:
$ nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
Мы должны установить нашу переменную «JAVA_HOME» в среде Hadoop:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
Снова нажмите «CTRL + O», чтобы сохранить содержимое файла.
Как настроить Apache Hadoop в Ubuntu
До этого момента мы успешно установили JAVA и Hadoop, создали пользователей Hadoop, настроили аутентификацию на основе ключей SSH. Теперь мы продвинемся вперед, чтобы показать вам, как настроить Apache Hadoop в системе Ubuntu. Для этого нужно создать два каталога: datanode и namenode внутри домашнего каталога Hadoop:
$ mkdir -p ~/hadoopdata/hdfs/namenode
$ mkdir -p ~/hadoopdata/hdfs/datanode
Мы обновим файл Hadoop «core-site.xml», добавив наше имя хоста, поэтому сначала подтвердите имя хоста вашей системы, выполнив эту команду:
$ hostname
Теперь откройте файл « core-site.xml » в редакторе nano:
$ nano $HADOOP_HOME/etc/hadoop/core-site.xml
Имя хоста нашей системы в «andreyex-VBox», вы можете добавить следующие строки с именем хоста системы в открытый файл Hadoop «core-site.xml»:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop.andreyex-VBox.com:9000</value> </property> </configuration>
Нажмите «CTRL + O» и сохраните файл.
В файле «hdfs-site.xml» мы изменим путь к каталогам «datanode» и «namenode»:
$ nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.name.dir</name> <value>file:///home/hadoopuser/hadoopdata/hdfs/namenode</value> </property> <property> <name>dfs.data.dir</name> <value>file:///home/hadoopuser/hadoopdata/hdfs/datanode</value> </property> </configuration>
Опять же, чтобы записать добавленный код в файл, нажмите «CRTL + O».
Затем откройте файл «mapred-site.xml» и добавьте в него приведенный ниже код:
$ nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Нажмите «CTRL + O», чтобы сохранить изменения, внесенные в файл.
Последний файл, который необходимо обновить, — это «yarn-site.xml». Откройте этот файл Hadoop в редакторе «nano»:
$ nano $HADOOP_HOME/etc/hadoop/yarn-site.xml
Запишите приведенные ниже строки в файл «yarn-site.xml»:
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
Мы должны запустить кластер Hadoop для работы с Hadoop. Для этого сначала отформатируем наш «namenode»:
$ hdfs namenode -format
Теперь запустите кластер Hadoop, выполнив следующую команду в своем терминале:
$ start-dfs.sh
Если в процессе запуска кластера Hadoop вы получаете сообщение “Could resolve hostname error”, вам необходимо указать имя хоста в файле «/etc/host»:
$ sudo nano /etc/hosts
Сохраните файл «/etc/host», и теперь все готово для запуска кластера Hadoop:
$ start-dfs.sh
На следующем шаге мы запустим службу пряжи Hadoop:
$ start-yarn.sh
Чтобы проверить статус всех сервисов Hadoop, выполните в терминале команду «jps»:
$ jps
Hadoop прослушивает порты 8088 и 9870, поэтому вам необходимо разрешить эти порты через брандмауэр:
$ firewall-cmd --permanent --add-port=9870/tcp
$ firewall-cmd --permanent --add-port=8088/tcp
Теперь перезагрузите настройки брандмауэра:
$ firewall-cmd --reload
Теперь откройте браузер и войдите в свой «namenode» Hadoop, введя свой IP-адрес с портом 9870.
Используйте порт 8080 со своим IP-адресом для доступа к диспетчеру ресурсов Hadoop:
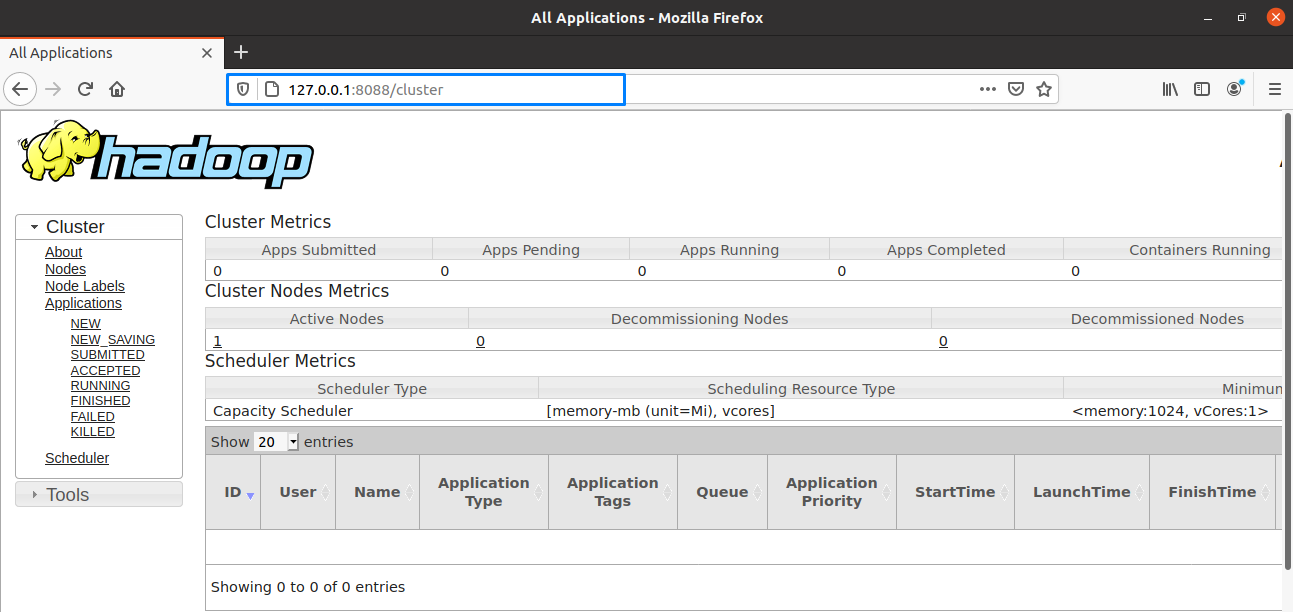
В веб-интерфейсе Hadoop вы можете найти «Каталог просмотра», прокрутив открытую веб-страницу вниз следующим образом:

Это все об установке и настройке Apache Hadoop в системе Ubuntu. Для остановки кластера Hadoop, вы должны остановить услуги «yarn» и «NameNode»:
$ stop-dfs.sh
$ stop-yarn.sh
Заключение
Для различных приложений с большими данными Apache Hadoop — это свободно доступная платформа для управления, хранения и обработки данных, которая работает на кластерных серверах. Это отказоустойчивая распределенная файловая система, допускающая параллельную обработку. В Hadoop модель MapReduce используется для хранения и извлечения данных из своих узлов. В этой статье мы показали вам метод установки и настройки Apache Hadoop в вашей системе Ubuntu.
Редактор: AndreyEx




