Как извлечь текст из скриншотов и изображений в Linux

Если вы часто делаете скриншоты, а потом жалеете, что не можете просто выделить на них текст, вам понравится то, что может сделать spectacle-ocr. Это быстрый, локальный и приватный процесс. С помощью spectacle-ocr вы можете преобразовать изображение в текст за один шаг.
С помощью этого метода можно извлекать текст практически из любых изображений, а не только из скриншотов. OCR (оптическое распознавание символов) не обращает внимания на то, откуда взялся текст: из скриншота, фотографии или отсканированного документа. Важно лишь то, насколько чётко и разборчиво текст выглядит на изображении.
Что такое Spectacle-OCR?
spectacle-ocr — это небольшая утилита, которая добавляет извлечение текста (OCR) непосредственно к снимкам экрана, сделанным с помощью инструмента для создания снимков экрана Spectacle в Linux (среды KDE).
Утилита spectacle-ocr объединяет две вещи:
- Инструмент для создания скриншотов Spectacle (для систем KDE)
- Система оптического распознавания Tesseract
Когда вы делаете скриншот с помощью Spectacle, вы можете выбрать «Извлечь текст» (или щёлкнуть правой кнопкой мыши по изображению → Извлечь текст). Затем скрипт:
- Запускает Tesseract OCR для распознавания текста на изображении.
- Копирует распознанный текст прямо в буфер обмена.
- Отображает уведомление на рабочем столе, подтверждающее успех или сообщающее об ошибке.
Это значит, что вы можете быстро выделить текст на скриншотах, например в диалоговом окне с ошибкой, в программе для просмотра PDF-файлов или на веб-изображении, без необходимости вводить текст вручную или загружать изображение в онлайн-инструмент оптического распознавания символов.
Как Это Работает
Вот как работает инструмент Spectacle-ocr:
- Он использует Tesseract OCR (поддерживает несколько языков; по умолчанию используется английский).
- Использует ImageMagick для автоматического изменения размера или предварительной обработки изображения для повышения точности распознавания текста.
- Определяет, используете ли вы Wayland или X11:
- Использует
wl-copyв Wayland. - Использует
xclipв X11.
- Использует
- Отправляет уведомления на рабочий стол с помощью
notify-send. - Очищает все временные файлы после запуска.
Зачем использовать Spectacle-OCR?
- Быстрый рабочий процесс: вы делаете снимок, вы извлекаете данные. Не нужно вручную открывать инструмент, импортировать изображение и ждать.
- Не нарушает конфиденциальность: вся обработка происходит локально. Вы не загружаете скриншот в какой-либо облачный сервис.
- Поддерживает несколько языков: Tesseract поддерживает множество языков, а скрипт позволяет использовать комбинации «lang=eng+…».
- Полезно для авторов блогов или разработчиков: если вы делаете скриншоты диалоговых окон с ошибками, фрагментов кода или документации, вы можете извлечь текст и вставить его в редактор вместо того, чтобы перепечатывать.
- Минимальные накладные расходы: скрипт использует существующие инструменты (ImageMagick, Tesseract, утилиты для работы с буфером обмена и уведомлениями), поэтому вам не нужно устанавливать громоздкий графический интерфейс, если он вам не нужен.
Установите spectacle-ocr в Linux
Способ 1. Использование установочного скрипта
Вы можете легко установить его с помощью сценария настройки:
git clone https://github.com/kbkozlev/spectacle-ocr cd spectacle-ocr bash setup.sh
Сценарий:
- Устанавливает зависимости (
tesseract-ocr,imagemagick,wl-clipboardилиxclip,libnotify-bin,desktop-file-utils). - Добавляет программу запуска «Извлечь текст» для файлов PNG.
- Обновляет базу данных вашего рабочего стола.
После этого в Spectacle в меню Экспорт появится опция Извлечь текст.
Обратите внимание, что вам необходимо установить Spectacle отдельно. Этот скрипт не установит его автоматически.
Способ 2. Установка вручную
Если вы не решаетесь использовать случайные скрипты, вот безопасный способ установки вручную.
Откройте терминал и установите необходимые зависимости. Например, в Debian, Ubuntu и их производных выполните команду:
sudo apt update sudo apt install tesseract-ocr imagemagick wl-clipboard xclip libnotify-bin desktop-file-utils
(Используйте wl-clipboard для Wayland, xclip для X11.)
Загрузите файлы spectacle-ocr:
git clone https://github.com/kbkozlev/spectacle-ocr.git cd spectacle-ocr
Скопируйте скрипт ocr.sh в папку, указанную в переменной PATH (например, ~/.local/bin), и сделайте его исполняемым:
install -Dm755 ocr.sh в ~/.local/bin/ocr.sh
Создайте ярлык на рабочем столе для опции «Выделить текст»:
mkdir -p ~/.local/share/applications
cat > ~/.local/share/applications/spectacle-ocr.desktop <<'EOF' [Desktop Entry] Name=Extract Text Exec=sh -c "nohup ~/.local/bin/ocr.sh %f >/dev/null 2>&1 &" MimeType=image/png; Icon=scanner Terminal=false Type=Application Categories=Utility; StartupNotify=false EOF
update-desktop-database ~/.local/share/applications || true
Теперь, когда у вас есть скриншот в формате PNG, вы можете щелкнуть по нему правой кнопкой мыши и в разделе «Открыть с помощью» → «Извлечь текст» запустить скрипт. Или воспользуйтесь опцией в меню «Экспорт» в Spectacle. Распознанный текст должен попасть в буфер обмена, и вы получите уведомление.
Если в какой-то момент вы захотите удалить:
rm -f ~/.local/share/applications/spectacle-ocr.desktop update-desktop-database ~/.local/share/applications || true rm -f ~/.local/bin/ocr.sh
Конфигурация
Вы можете отредактировать скрипт ocr.sh и изменить LANG="eng" для поддержки нескольких языков оптического распознавания символов, например:
LANG="eng+deu"
Расширьте список поддерживаемых типов файлов, включив в него не только PNG, изменив MIME-типы файла .desktop .
Извлечение текста из скриншотов с помощью spectacle-ocr
- Сделайте скриншот с помощью Spectacle.
- Выберите Экспорт → Извлечь текст.
- Распознанный текст появится в буфере обмена, а на рабочем столе появится уведомление об успешном выполнении.
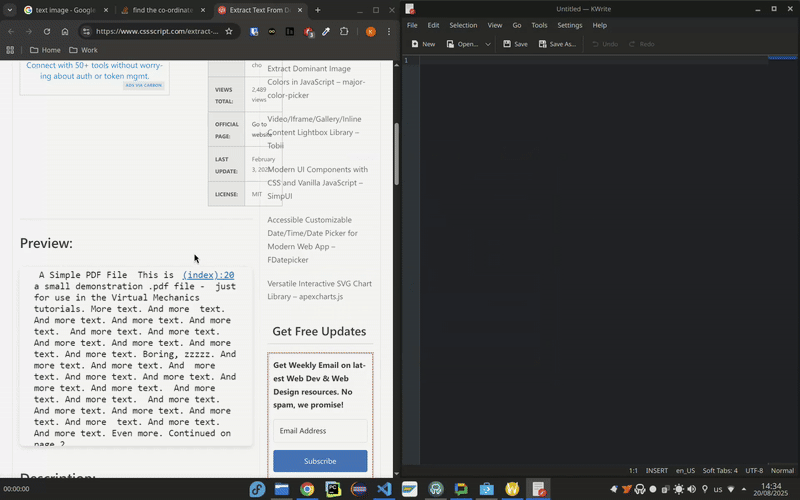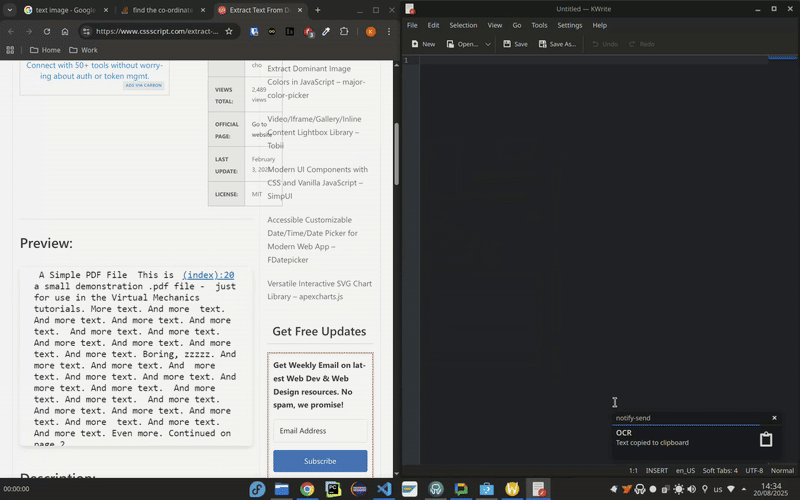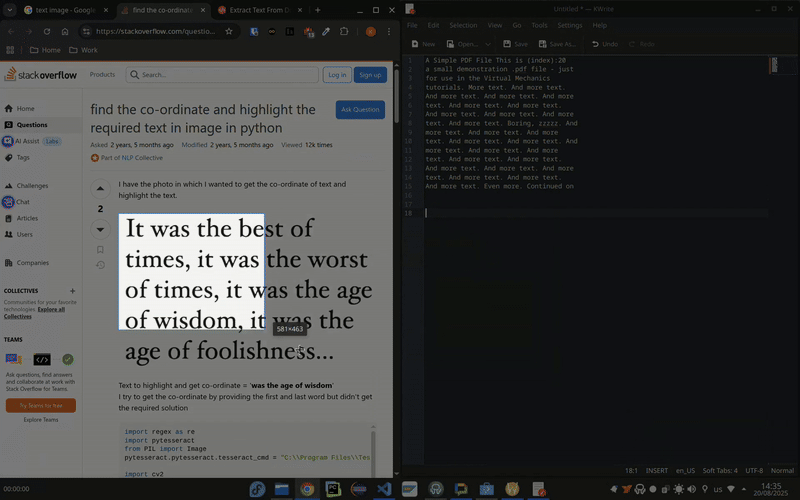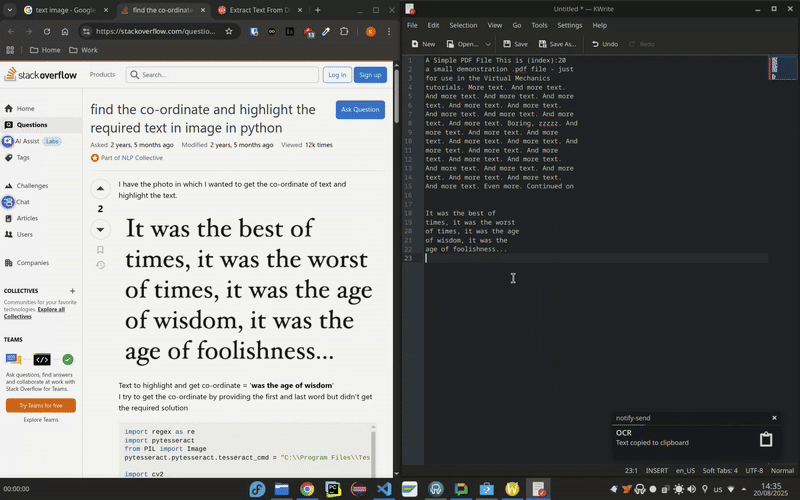
Демонстрация ocr
Извлечение текста из изображений
Поскольку в этом скрипте используется механизм оптического распознавания символов Tesseract, вы можете использовать его напрямую для извлечения текста из любого изображения. На самом деле вам не обязательно использовать какой-то конкретный инструмент для создания скриншотов. Скрипт работает с любым изображением, независимо от того, как оно было создано (Spectacle, Ksnip, Flameshot или даже фотография, сделанная на камеру).
Для этого просто передайте путь к изображению в качестве аргумента, а скрипт сделает всё остальное автоматически.
ocr.sh ~/Pictures/screenshot.png ocr.sh ~/Downloads/photo-of-book.jpg ocr.sh ~/Desktop/error_dialog.png
Просто убедитесь, что изображения чёткие, а текст легко читается!
Советы по достижению наилучших результатов распознавания текста
- Убедитесь, что на вашем скриншоте есть четкий текст (высокая контрастность, читаемый шрифт). Качество оптического распознавания символов снижается, если текст размыт или имеет низкое разрешение.
- Если ваш инструмент для создания скриншотов сохраняет изображение небольшого размера, вы можете его увеличить.
- Если вы используете несколько языков (например, английский и хинди), установите языковые пакеты Tesseract (например,
tesseract-ocr-hin) и соответствующим образом измените строкуLANG="eng+hin"вocr.sh. - Если вы столкнулись с такими ошибками, как проблемы с «policy.xml» в ImageMagick (некоторые дистрибутивы ограничивают определённые операции), проверьте
/etc/ImageMagick-*/policy.xml. - Если вы редко пользуетесь Spectacle и вместо этого используете другой инструмент, вы всё равно можете изменить путь к скрипту или использовать другой инструмент для создания скриншотов и тот же скрипт OCR с небольшими изменениями. Вам может помочь быстрый поиск в интернете или использование искусственного интеллекта.
Когда технология Spectacle-OCR может оказаться неидеальной
Хотя технология Spectacle-ocr работает хорошо, в некоторых ситуациях вам может понадобиться другой подход:
- Если вы используете среду рабочего стола, отличную от KDE (GNOME, XFCE), и не хотите устанавливать Spectacle или зависимости Qt/KDE. В этом случае другой способ создания скриншотов и распознавания текста может показаться более привычным.
- Если вам нужно активно аннотировать/редактировать скриншоты (стрелки, размытие, стикеры), а также извлекать текст, возможно, вам больше подойдёт инструмент, который объединяет функции захвата → аннотирования → оптического распознавания символов в одном.
- Если ваш инструмент для создания скриншотов сохраняет изображения в формате, отличном от PNG (например, в формате JPEG), вам следует изменить
.desktopMimeTypeнаimage/jpeg;. По умолчанию используетсяimage/png;.
Краткие сведения
spectacle-ocr выступает в качестве локального, безопасного оптического распознавания символов между Spectacle и Tesseract, позволяя извлекать текст из скриншотов одним щелчком мыши. Он лёгкий, легко интегрируется с KDE и не зависит от облачных сервисов.
Он позволяет одним щелчком мыши преобразовать изображение в текст, который можно скопировать в буфер обмена. Он использует надёжные бесплатные компоненты с открытым исходным кодом (Tesseract, ImageMagick).
Если вам нужен быстрый и простой способ извлечения текста из скриншотов в Linux, spectacle-ocr может стать хорошим выбором.
Более подробную информацию можно найти в репозитории spectacle-ocr на GitHub.
Редактор: AndreyEx
Важно: Данная статья носит информационный характер. Автор не несёт ответственности за возможные сбои или ошибки, возникшие при использовании описанного программного обеспечения.




