Руководство для начинающих по системным журналам в Linux

Старые добрые системные журналы по-прежнему актуальны в эпоху системных журналов. Изучите основы ведения журнала с помощью syslogd в этом руководстве.
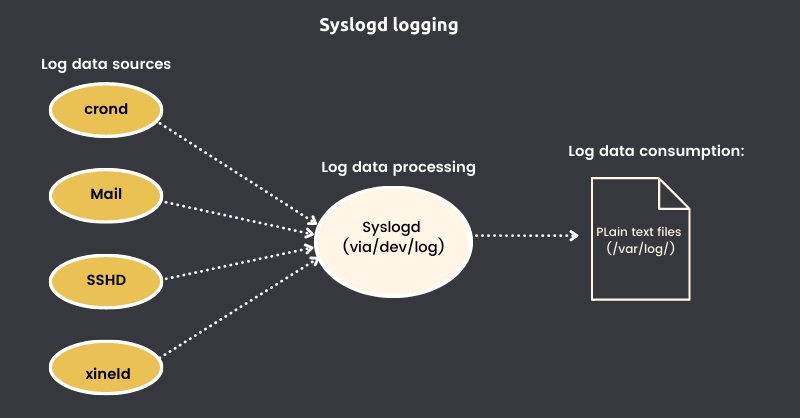
Десятилетиями журналирование в Linux управлялось демоном syslogd.
Syslogd будет собирать сообщения журнала, которые системные процессы и приложения отправляли на псевдоустройство /dev/log. Затем он будет направлять сообщения в соответствующие текстовые файлы журнала в каталоге /var/log/.
Syslogd будет знать, куда отправлять сообщения, поскольку каждое из них включает заголовки, содержащие поля метаданных (включая отметку времени, а также источник и приоритет сообщения).
Вслед за неумолимой, завоевавшей мир силой systemd журналирование Linux теперь также обрабатывается journald. Мы говорим еще и потому, что syslogd никуда не делся, и вы по-прежнему можете найти большинство его традиционных лог-файлов в /var/log/. Но вы должны знать, что в городе появился новый шериф, имя которого (в командной строке) — journalctl.
Но эта статья не о журнале. Основное внимание здесь уделяется systemd, так что давайте углубимся в него.
Ведение журнала с помощью syslogd
Все журналы, созданные событиями в системе syslogd, добавляются в файл /var/log/syslog. Но, в зависимости от их идентифицирующих характеристик, они также могут быть отправлены в один или несколько других файлов в том же каталоге.
В syslogd способ распространения сообщений определяется содержимым файла 50-default.conf, находящегося в каталоге /etc/rsyslog.d/.
В этом примере 50-default.conf показано, как сообщения журнала, помеченные как относящиеся к cron, будут записываться в файл cron.log. В этом случае звездочка (*) указывает syslogd отправлять записи с любым уровнем приоритета (в отличие от одного уровня, такого как emerg или err):
cron.* /var/log/cron.log
Работа с лог-файлами syslogd не требует специальных инструментов, таких как journalctl. Но если вы хотите в этом преуспеть, вам необходимо знать, какая информация хранится в каждом из стандартных файлов журналов.
В таблице ниже перечислены наиболее распространенные файлы журналов syslogd и их назначение.
| Имя файла | Цель |
|---|---|
| auth.log | Системная аутентификация и события безопасности |
| boot.log | Запись событий, связанных с загрузкой |
| dmesg | События кольцевого буфера ядра, связанные с драйверами устройств |
| dpkg.log | События управления пакетами программного обеспечения |
| kern.log | События ядра Linux |
| syslog | Сбор всех журналов |
| wtmp | Отслеживает сеансы пользователей (доступ через команды who и last) |
Кроме того, отдельные приложения иногда записывают в свои собственные файлы журналов. Вы также часто будете видеть целые каталоги, такие как /var/log/apache2/ или /var/log/mysql/, созданные для получения данных приложения.
Перенаправление журнала также можно контролировать с помощью любого из восьми уровней приоритета в дополнение к символу * (для всех уровней приоритета), который вы видели ранее.
| Уровень | Описание |
|---|---|
| debug | Полезно для отладки |
| info | Информационный |
| notice | Нормальные условия |
| warn | Условия, требующие предупреждений |
| err | Условия ошибки |
| crit | Критические условия |
| alert | Требуются немедленные действия |
| emerg | Система непригодна для использования |
Управление файлами журналов с помощью sysglogd
По умолчанию syslogd обрабатывает ротацию, сжатие и удаление журналов за кулисами без какой-либо помощи с вашей стороны. Но вы должны знать, как это делается, если у вас когда-нибудь появятся бревна, нуждающиеся в специальной обработке.
Какой особой обработки может потребовать простое бревно? Что ж, предположим, что ваша компания должна соответствовать правилам отчетности о транзакциях, связанным с нормативными или отраслевыми стандартами, такими как Сарбейнс-Оксли или PCI-DSS. Если записи вашей ИТ-инфраструктуры должны оставаться доступными в течение более длительного периода времени, вам определенно нужно знать, как найти путь к ключевым файлам.
Чтобы увидеть систему logrotate в действии, перечислите часть содержимого каталога /var/log/. Например, файл auth.log представлен в трех разных форматах:
- auth.log — текущая активная версия, в которую записываются новые сообщения авторизации.
- auth.log.1 — самый последний файл, который был выведен из эксплуатации. Он сохраняется в несжатом формате, чтобы его было легче быстро вызвать обратно в действие, если это необходимо.
- auth.log.2.gz — старая коллекция (как видно из расширения файла .gz в следующем листинге), сжатая для экономии места.
Через семь дней, когда наступит следующая дата ротации, auth.log.2.gz будет переименован в auth.log.3.gz, auth.log.1 будет сжат и переименован в auth.log.2.gz, auth.log. станет auth.log.1, и будет создан новый файл с именем auth.log.
Цикл ротации журнала по умолчанию управляется в файле /etc/logrotate.conf. Значения, показанные в этом списке, заменяют файлы после одной активной недели и удаляют старые файлы через четыре недели.
# еженедельно чередуйте файлы журналов weekly # сохраняйте отставание на 4 недели rotate 4 # создавайте новые (пустые) файлы журналов после поворота старых create # пакеты помещают информацию о ротации журналов в этот каталог include /etc/logrotate.
Каталог /etc/logrotate.d/ также содержит настроенные файлы конфигурации для управления ротацией журналов отдельных служб или приложений. Перечисляя содержимое этого каталога, вы видите эти файлы конфигурации:
$ ls /etc/logrotate.d/ apache2 apt dpkg mysql-server rsyslog samba unattended-upgrade
Вы можете просмотреть их содержимое, чтобы увидеть, какая у них конфигурация ротации журналов.
Как читать файлы системного журнала
Вы знаете, что у вас есть дела поважнее, чем чтение миллионов строк записей в журнале.
Здесь следует полностью избегать использования команду cat. Он просто выведет тысячи строк на ваш экран.
Мы предлагаем использовать команду grep для фильтрации текста через файлы.
Использование команды tail -f позволяет вам читать текущий файл журнала в режиме реального времени. Вы можете комбинировать его с grep для фильтрации нужного текста.
В некоторых случаях может потребоваться доступ к сжатым старым журналам. Вы всегда можете сначала извлечь файл, а затем использовать grep, less и другие команды для чтения его содержимого, однако есть вариант получше. Существуют z-команды, такие как zcat, zless и т. д., которые позволяют работать со сжатыми файлами без их явного извлечения.
Практический пример анализа журнала
Вот очевидный пример, который будет искать в файле auth.log доказательства неудачных попыток входа в систему. Поиск слова «failure»
вернет любую строку, содержащую фразу «Authentication failure».
Проверяя это время от времени, вы можете обнаружить попытки компрометации учетной записи, угадывая правильный пароль. Любой может испортить пароль один или два раза, но слишком много неудачных попыток должны вызвать у вас подозрения:
$ cat /var/log/auth.log | grep 'Authentication failure' Sep 6 09:22:21 workstation su[21153]: pam_authenticate: Authentication failure
Если вы из тех администраторов, которые никогда не ошибаются, то этот поиск может оказаться пустым. Вы можете гарантировать себе по крайней мере один результат, вручную сгенерировав запись в журнале с помощью программы под названием logger. Попробуйте сделать что-то вроде этого:
logger "Authentication failure"
Вы также можете предварительно засеять подлинную ошибку, войдя в учетную запись пользователя и введя неправильный пароль.
Как видите, grep сделал всю работу за вас, но все, что вы видите по результатам, это то, что произошла ошибка аутентификации. Разве не было бы полезно знать, чей счет был задействован? Вы можете расширить результаты, возвращаемые grep, сказав ей включить строки непосредственно до и после совпадения.
В этом примере совпадение печатается вместе с линиями вокруг него. Это говорит вам, что кто-то, использующий учетную запись andrey, безуспешно пытался использовать su (сменить пользователя) для входа в учетную запись студии:
$ cat /var/log/auth.log | grep -C1 failure Sep 6 09:22:19 workstation su[21153]: pam_unix(su:auth): authentication failure; logname= uid=1000 euid=0 tty=/dev/pts/4 ruser=andrey rhost= user=studio Sep 6 09:22:21 workstation su[21153]: pam_authenticate: Authentication failure Sep 6 09:22:21 workstation su[21153]: FAILED su for studio by andrey
Что дальше?
Знать основы — это одно, а применять эти знания — совсем другое. Однако знание основ помогает в различных ситуациях.
Теперь, когда вы знаете основы системных журналов в Linux, вам может быть немного легче работать с журналами.
Редактор: AndreyEx




