Что такое uptime и почему 99% — это не всегда хорошо
В статье мы объясняем, что такое uptime — ключевой показатель доступности современных IT-сервисов и серверов, и почему для бизнеса важно не довольствоваться «вроде работает». Даже 99% uptime означает часы простоя в месяц, которые могут стоить клиентской базы и репутации, тогда как 99,99% и выше переводят систему в разряд практически непрерывно доступных. Мы разбираем, как вычисляется uptime, зачем нужна проверка доступности сервисов и почему SLA — это не гарантия абсолютной безотказности.
Что такое uptime сервера
Uptime сервера — это показатель, который показывает, сколько времени сервер работает непрерывно и остаётся доступным без простоев или отключений. Проще говоря, это тот период, когда сервер онлайн, отвечает на запросы и выполняет свои задачи, и пользователи могут к нему подключаться без прерываний.
Как это измеряется
Uptime измеряется в процентах за определённый период (например, за месяц или год). Процент uptime показывает долю времени, в течение которого сервер был доступен по отношению к общему времени. Если uptime сервера составляет 99,9%, это означает, что сервер работал почти всё время, а простой составил лишь маленькую часть.
Почему uptime сервера важен
Сервер — это сердце любой онлайн-системы: он хранит данные, обрабатывает запросы и обеспечивает работу вашего сайта или приложения. Если сервер недоступен — сервис недоступен: пользователи не могут зайти на сайт, сделать заказ или использовать продукт. Размер uptime напрямую отражает надёжность и стабильность работы сервера.
Uptime и downtime — противоположные понятия
Uptime всегда рассматривается вместе с downtime — временем, когда сервер недоступен. Увеличение uptime означает уменьшение downtime, а высокий уровень uptime показывает, что сервер крайне редко «падает» и прерывает работу.
Как считается доступность сервисов
Формула расчёта uptime
Чтобы понять, насколько стабильно работает сервис, uptime принято выражать в процентах:
Uptime (%) = (Общее время — Время простоя) / Общее время × 100
То есть сначала считаем, сколько времени система была доступна без простоев, а затем делим на всё время наблюдения и умножаем на 100 %.
Пример: если сервис был недоступен 30 минут за месяц (43 200 мин), то uptime = (43 200–30) / 43200 × 100 ≈ 99,93%.
Откуда берутся проценты доступности
Процент uptime отражает долю времени, когда сервис был доступен. SLA — это соглашение с клиентами, где провайдер обязуется держать доступность не ниже определённого уровня (например, 99,9 % или 99,99 %). Чем выше процент, тем менее вероятны простои и тем меньше потерянное время.
Важно: процент uptime не учитывает качество работы (например, скорость ответа сервера). Но он даёт базовое измерение надёжности сервиса для клиентов и бизнеса.
Почему даже 1% простоя — это много
На словах 99 % звучит почти честно, но на практике это означает значительные простои:
- при 99 % uptime сервис может быть недоступен более 7 часов в месяц — и это только один месяц.
Даже если простой случается в нерабочие часы, он всё равно может ударить по бизнес-процессам и пользовательскому опыту — от внутренних инструментов до публичных сайтов и API.
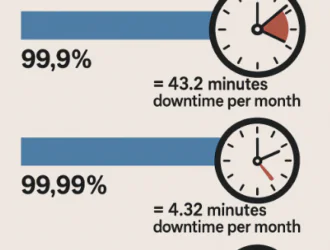
99%, 99,9% и 99,99% — в чём разница
Проценты uptime — это не просто красивые цифры: каждая дополнительная «девятка» сильно сокращает допустимое время простоя.
Сколько времени простоя при uptime 99 99
Вот сколько времени сервис может быть не доступен за месяц, в зависимости от уровня uptime (примерно, при периоде 30 дней = 43 200 минут):
| Uptime | Простой в месяц |
|---|---|
| 99 % | ≈ 7 ч 18 мин |
| 99,9 % | ≈ 43 мин |
| 99,99 % | ≈ 4 мин |
| 99,999 % | ≈ 0,26 мин (~16 сек) |
Это значит, что uptime 99,99 — это примерно 4–5 минут простоя в месяц, что уже порядка 90 % меньше, чем при 99 % SLA.

Почему uptime 99 99 — принципиально другой уровень
Переход от 99 % к 99,99 % — это не просто ещё одна цифра: это порядки меньшее доступное время падений. Такой уровень обычно достигается за счёт архитектурных решений, включая резервирование серверов, гео-разнесённые кластеры, отказоустойчивую инфраструктуру. Для бизнеса это значит:
- клиенты почти не замечают перерывов;
- внутренние процессы работают непрерывно;
- риск потерь из-за простоев снижается многократно.
Почему 99% — это риск для бизнеса
Реальные последствия простоев
Даже если кажется, что несколько часов в месяц — не много, для бизнеса это может быть критично:
- потеря клиентов, если сервис недоступен во время пиковых часов;
- негативные отзывы и снижение доверия к бренду;
- сбои автоматизации и внутренних процессов.
Когда сервис «падает», даже если клиенты спят
Простой может случиться в любое время — и он не обязательно совпадает с рабочими часами. Если система падает ночью, проблемы могут не проявиться сразу, но утром это приведёт к цепочке последствий:
- накопление ошибок, которые сложно быстро устранить;
- рабочие процессы останавливаются;
- техподдержка отвлекается на восстановление.
Для каких систем 99% недопустим
99 % uptime подходит разве что для некритичных внутренних инструментов, где простой не влечёт серьёзных потерь. Но если продукт:
- обслуживает клиентов 24/7;
- генерирует выручку в режиме реального времени;
- зависит от внешних API и интеграций;
то 99 % может быть слишком низким уровнем доступности, который нарушает SLA и приводит к потерям.
Как проводят проверку доступности сервисов
Зачем нужна проверка доступности сервисов
Проверка доступности сервисов — это регулярный мониторинг того, доступен ли сервис для пользователей и выполняет ли свои функции. Он помогает увидеть, работает ли система так, как заявлено, и зафиксировать фактические простои или деградацию. Это критично, потому что аналитика по uptime и доступности — это не просто чтение отчётов, а активный контроль за состоянием сервиса в реальном времени.
Такой мониторинг может включать автоматические запросы к API, проверку отклика веб-страниц, тесты основных транзакций и т.д. Эти проверки осуществляются так часто, как нужно бизнесу — от секундных интервалов до нескольких минут, в зависимости от критичности сервиса.
Почему нельзя верить только отчётам провайдера
Отчёты провайдера по SLA или uptime часто не отражают реального состояния сервиса для конечного пользователя. Провайдер может фиксировать uptime на уровне инфраструктуры (например, сервер был включён), но это не значит, что все ключевые функции работали корректно или были доступны из всех регионов.
Кроме того, провайдеры иногда исключают запланированные работы, форс-мажор и другие обстоятельства из подсчёта SLA — и тогда отчёт может показывать высокий уровень, даже если пользователи испытывали проблемы. Вот почему собственный мониторинг важен: он независим, показывает реальный опыт всех пользователей и помогает раньше обнаружить проблемы, прежде чем они перерастут в масштабный простой.
Роль мониторинга
Мониторинг доступности — это не только уведомления о падении сервиса, но и анализ трендов, измерение ключевых метрик (время ответа, частота ошибок, процент неудачных запросов), получение алертов и построение логов. Это помогает:
- фиксировать инциденты в момент возникновения;
- видеть, насколько часто и в каком размере происходят сбои;
- определять, влияет ли это на SLA и когда стоит предпринимать меры.
Мониторинг фактически становится источником правды о доступности сервиса — в отличие от отчетов провайдера, которые строятся по собственным данным и правилам. Это особенно важно для SLA, где любая минута простоев может стоить денег и репутации.
Что на самом деле означает SLA по uptime
Почему SLA — это не гарантия бесперебойной работы
SLA (Service Level Agreement) — это договор между провайдером и клиентом, где прописаны параметры сервиса, которые поставщик обязуется обеспечивать. В SLA обычно указываются метрики доступности, время отклика, обязанности сторон, компенсации за нарушения и другие условия. Важно понимать, что SLA — это обещание уровня сервиса, а не техническое совершенство. Даже с высоким SLA (например, 99,99 %) возможны простои — просто их количество и длительность должны быть ниже оговоренного уровня.
Ограничения SLA по доступности
Обычно SLA описывает:
- что считается простоем (например, сервис недоступен по API или веб-интерфейсу);
- когда считается нарушение SLA;
- что исключается из расчёта (например, плановые технические работы, форс-мажор, действия третьих сторон);
- какие компенсации предоставляются, если SLA нарушен.
Это значит, что даже если сервис был недоступен, провайдер может не признать это нарушением SLA, если простой произошёл в оговоренное «окно обслуживания» или был вызван внешними факторами. Поэтому SLA не может гарантировать абсолютное отсутствие простоев — это скорее правовой механизм фиксации ответственности и компенсации.
На что обращать внимание в договоре
Когда вы оцениваете SLA, важно смотреть:
- конкретный процент uptime, который гарантируется (99%, 99,9%, 99,99%);
- как измеряется доступность (с каких точек, по каким условиям);
- исключения из расчёта (плановое обслуживание, форс-мажор);
- механизмы компенсации, если обещанный уровень не достигнут.
Понимание этих условий помогает бизнесу реалистично оценивать риски и выбирать провайдера, который действительно будет соответствовать требованиям по uptime, а не только красиво выглядит в договоре.
Почему хороший дата-центр — это отказоустойчивый сервис
Что такое отказоустойчивость
Отказоустойчивость — это способность системы продолжать работу даже при отказе одного или нескольких её компонентов. В контексте дата-центров это означает, что при выходе из строя оборудования (например, сервера, блока питания, канала связи) сервис остаётся доступным и работает как прежде. Такая архитектура исключает «единую точку отказа» — то есть ситуацию, когда ломается один элемент и всё падает.
Отказоустойчивость достигается за счёт аппаратной избыточности и инфраструктурных решений, например, кластеризации серверов, дублирования каналов питания и сетей, резервирования компонентов, а также автоматического переключения на резервные узлы при сбое.

Как инфраструктура влияет на доступность
Инфраструктура — это не просто «железо в комнате»; она определяет, насколько услуга устойчива к сбоям. Классические инженерные подходы включают:
- Дублирование источников питания и охлаждения — если один из блоков выходит из строя, другой подхватывает нагрузку без простоя.
- Резервные пути данных и сетей — альтернативные каналы связи, чтобы сбой одного не повлиял на работу сервиса.
- Concurrent maintainability (параллельное обслуживание) — возможность выполнять технические работы без остановки сервисов.
- Высокие уровни Tier (например Tier-III и Tier-IV) — архитектурные классы, где отказ одного компонента не влияет на доступность сервиса.
Согласно классификации Uptime Institute, дата-центры с более высоким уровнем отказоустойчивости имеют значительно меньше времени простоя в год — например, Tier-III с резервированием оборудования может обеспечивать ~99,98% доступности, а Tier-IV с полной отказоустойчивой архитектурой — ~99,995 % доступности. Такой подход означает, что simple hardware failures, maintenance events or component failures don’t lead to service downtime, что напрямую влияет на uptime сервера и бизнес-доступность сервиса.
Почему надёжность начинается не с процентов
Проценты — это только агрегированные цифры в отчётах SLA, но сам характер инфраструктуры определяет, насколько реально устойчив сервис к сбоям. Если архитектура построена так, что один отказ приводит к простоям, то даже «99,9% uptime» не спасёт сервис от заметных перерывов в работе. Инфраструктура же, построенная по принципам отказоустойчивости, сокращает риски и делает систему устойчивой к реальным условиям эксплуатации. Переход к отказоустойчивой архитектуре включает:
- Внедрение резервирования и кластеров, чтобы сбой одного сервера автоматически перекрывался другими.
- Использование Tier-уровней и стандартов для оценки реальной надёжности, а не только обещаний в SLA.
- Акцент на инженерные решения (питание, сети, охлаждение), которые устраняют точки отказа.
Именно это делает uptime сервера реальным, а не «идеальным на бумаге».
Заключение
Хотя 99% uptime звучит неплохо на бумаге, на практике это означает, что сервис всё ещё может падать на часы каждый месяц, и такие простои заметят как пользователи, так и бизнес. Уровень 99,99% кардинально меняет ситуацию: простой сокращается до нескольких минут в месяц, и сервис становится практически непрерывно доступным. Настоящий uptime — это не просто цифра в SLA, а результат грамотной инфраструктуры и отказоустойчивости, когда сбои не приводят к остановке работы, а система остаётся стабильной и надёжной для пользователей и бизнеса.
Редактор: AndreyEx




