Устранение неполадок в медленных SQL-запросах для повышения производительности

Медленные SQL-запросы могут существенно повлиять на производительность базы данных и приложений, которые полагаются на нее. Неэффективные запросы могут привести к перегрузке базы данных, что приведет к снижению производительности и увеличению времени отклика пользователей.
Это может привести к ухудшению взаимодействия с пользователем, поскольку пользователям, возможно, придется долго ждать выполнения своих запросов. Медленные запросы также потребляют значительные ресурсы процессора и памяти, что может повлиять на производительность других процессов, запущенных на том же сервере базы данных.
По этим причинам важно знать, как писать эффективные SQL-запросы для вашей базы данных, чтобы они выполнялись оптимально. В этой статье рассматривается, как выявить медленные запросы в SQL Server, определить их причину и эффективно устранить их.
Почему ваши SQL-запросы выполняются медленно
При попытке исправить низкую производительность базы данных первым шагом является определение того, выполнение каких запросов занимает много времени. Чтобы отследить медленно выполняющиеся запросы в SQL Server, вы можете использовать представление sys.dm_exec_query_stats.
Два важных столбца, возвращаемых этим представлением: last_elapsed_time и last_worker_time. В столбце last_elapsed_time показано, сколько времени потребовалось для выполнения самого последнего запроса в микросекундах. В столбце last_worker_time указано, сколько времени задача потратила на выполнение работы, исключая любое время, когда она была заблокирована. Если столбец last_worker_time значительно ниже, чем столбец last_elapsed_time, это может указывать на то, что другой процесс заставляет запрос ждать, прежде чем он сможет быть запущен. Это известно как ожидающий запрос.
Запрос неэффективен, если велико как затраченное, так и рабочее время. Обратите внимание, что как ожидающие, так и выполняющиеся запросы могут способствовать замедлению работы базы данных. Идентификация и обработка обоих типов запросов необходимы для оптимизации производительности базы данных.
Ожидающие запросы
Ожидающий запрос не может быть выполнен до тех пор, пока ресурс не станет доступным. Ожидания ресурсов описывают запросы, которые должны дождаться снятия блокировки, прежде чем они смогут выполняться. Ожидания в очереди возникают, когда запрос ожидает получения достаточного количества ресурсов для выполнения запроса. Наконец, внешние ожидания, как следует из названия, определяют запросы, ожидающие внешнего объекта, такого как ответ от связанного сервера. Если многие запросы ожидают ресурсов, это может привести к накоплению запросов, что приведет к замедлению работы.
Первым шагом для устранения узких мест, связанных с ожиданием, является определение причины ожидания запроса. Вы можете использовать представление sys.dm_os_wait_stats для определения наиболее распространенных ожиданий в системе. В этом представлении также хранятся данные для исторических запросов, которые могут быть сброшены администратором базы данных или при перезапуске базы данных. В зависимости от вашего варианта использования вы можете скопировать данные в это представление, чтобы отслеживать проблемы с производительностью с течением времени.
Увеличение количества доступного оборудования иногда может разрешить проблему ожидания ресурсов или очереди. В других случаях вы можете использовать подсказки по запросу, такие как MAXDOP, чтобы контролировать степень параллелизма запроса и уменьшить количество ожиданий. Внешние ожидания немного сложнее разрешить, поскольку внешняя задача может быть неэффективной и нуждаться в диагностике.
Запущенные запросы
Выполняемый запрос — это запрос, для которого общее время выполнения велико. Выполняемый запрос может медленно возвращать результаты пользователям. Если он использует слишком много ресурсов, это может привести к замедлению других процессов.
Вы можете использовать план запроса, чтобы понять, что вызывает узкие места в работе. Чтобы просмотреть план запроса в SQL Server, запустите инструкцию SET STATISTICS PROFILE ON перед запуском запроса. Это предоставляет план непосредственно после результатов запроса. Другой вариант — использовать представление sys.dm_exec_query_plan, которое возвращает план для кэшированного запроса.
При изучении плана запроса ищите операторы, которые стоят дороже других, такие как тип соединений, отсутствие использования индекса и кэширование. Вы также можете искать операторы с несколькими строками или большим объемом данных, проходящих через них, что может способствовать возникновению узких мест.
Для решения медленно выполняемых запросов может потребоваться изменение логики запроса, добавление индексов к таблицам или обновление статистики таблицы.
Хранимые процедуры
Устранение неполадок с медленно выполняемыми хранимыми процедурами может быть особенно сложным по нескольким причинам. Когда хранимая процедура выполняется в первый раз, оптимизатор запросов создает план выполнения и сохраняет его в кэше процедур. Этот кэшированный план будет использоваться при выполнении хранимой процедуры в будущем. Чтобы решить эту проблему, вы можете запустить команду EXEC sp_recompile ‘<ИМЯ ПРОЦЕДУРЫ>’ для обновления плана запроса.
Более того, хранимые процедуры могут содержать несколько запросов, а также могут использовать переменные, циклы и другие программные конструкции, что затрудняет понимание того, как они выполняются.
Рассмотрим следующий пример медленно работающей хранимой процедуры, которая вычисляет некоторую статистику о заказах для данного кода страны:
CREATE PROCEDURE GetOrdersByCountry @Country VARCHAR(50)
AS
BEGIN
SELECT COUNT(*) as orders, SUM(TotalAmount) as total_amount
FROM Orders
WHERE Country = @Country;
END;
Выполните эту процедуру, запустив команду execute и передав ей код страны:
EXECUTE GetOrdersByCountry 'UK';
После выполнения хранимой процедуры вы можете посмотреть, как она выполнялась, используя sys.dm_exec_query_stats представление. Вы можете применить CROSS APPLY к представлению sys.dm_exec_sql_text, как показано ниже, чтобы увидеть выполненную инструкцию и last_worker_time и last_elapsed_time.
SELECT
qs.last_worker_time,
qs.last_elapsed_time,
SUBSTRING(
st.text,
(qs.statement_start_offset / 2) + 1,
(
(
CASE qs.statement_end_offset WHEN -1 THEN DATALENGTH(st.text) ELSE qs.statement_end_offset END - qs.statement_start_offset
) / 2
) + 1
) AS statement_text
FROM
sys.dm_exec_query_stats AS qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS st
ORDER BY qs.last_execution_time;
Это дает следующий вывод для запроса:
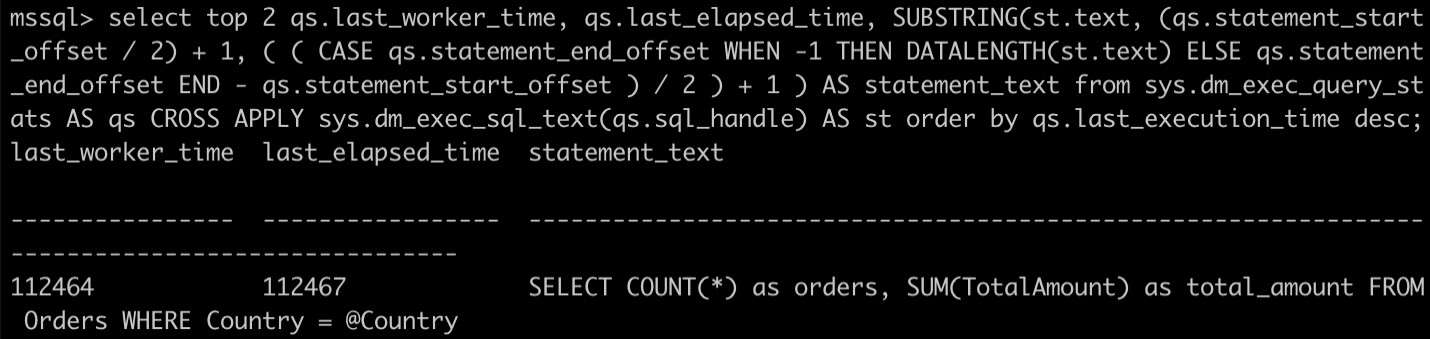
Рис. 1: Выходные данные для запросов last_worker_time и last_elapsed_time
Время last_worker_time и last_elapsed довольно схожи, поэтому это не пример ожидающего запроса. Тем не менее, общее время велико, поскольку запрос неэффективен.
Чтобы исследовать хранимую процедуру, запустите SET STATISTICS PROFILE, а затем снова запустите хранимую процедуру. По результатам процедуры вы получите таблицу данных, содержащую каждый раздел плана запроса и его стоимость.
Выполнение этого перед запуском хранимой процедуры выводит таблицу. Обратите внимание на столбцы LogicalOp, Argument, DefinedValues и TotalSubtreeCost. Столбцы LogicalOp, Argument и DefinedValues сообщают вам, какая операция выполняется и над каким объектом. TotalSubtreeCost сообщает вам, сколько стоит эта операция.
Для хранимой процедуры этот вывод определяет следующую операцию как наиболее дорогостоящую:
Clustered Index Scan OBJECT:([master].[dbo].[Orders].[PK__Orders__C3905BAF72AEC27B]), WHERE:([master].[dbo].[Orders].[Country]=[@Country])
Это показывает, что запрос выполняет сканирование кластеризованного индекса в таблице при выполнении части запроса WHERE. Сканирование кластеризованного индекса обычно выполняется медленнее, чем операция поиска, поскольку она извлекает все строки из таблицы или представления путем сканирования всего кластеризованного индекса. С другой стороны, операция поиска использует индекс для непосредственного поиска строк, соответствующих указанным критериям, и, следовательно, выполняется быстрее.
Это показывает, что вам необходимо добавить индекс в таблицу Orders, чтобы ускорить хранимую процедуру. Вы можете добавить индекс в столбцы Country и TotalAmount с помощью следующей команды:
CREATE INDEX IX_Orders_Country_Total ON Orders (Country, TotalAmount);
Теперь снова запустите хранимую процедуру и проверьте время выполнения с помощью представления sys.dm_exec_query_stats.
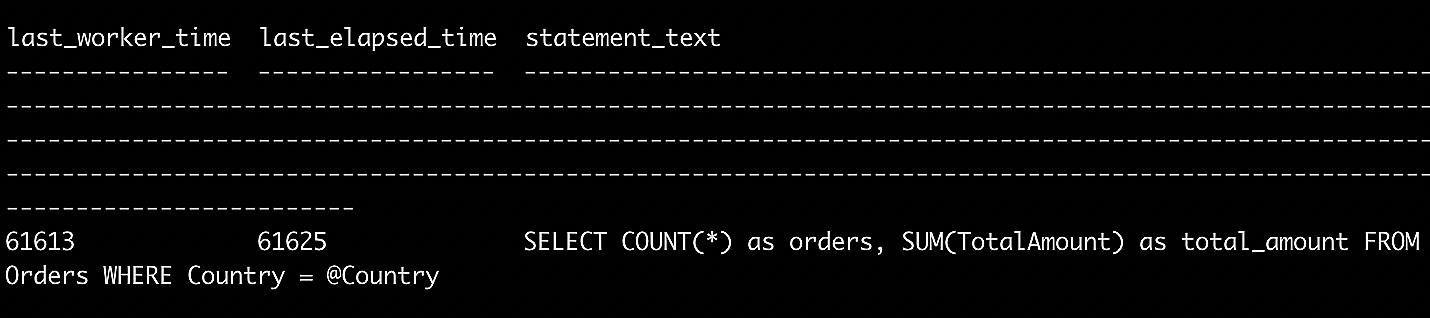
Рис. 2. Запуск хранимой процедуры с использованием представления sys.dm_exec_query_stat
Вы можете видеть, что вы почти вдвое сократили время выполнения хранимой процедуры, просто добавив индекс.
Если вы взглянете на план запроса, вы также должны увидеть, что предыдущее сканирование кластеризованного индекса теперь изменилось на поиск по индексу следующим образом:
Index Seek OBJECT:([master].[dbo].[Orders].[IX_Orders_Country_Total]), SEEK:([master].[dbo].[Orders].[Country]=[@Country]) ORDERED FORWARD [master].[dbo].[Orders].[TotalAmount]
Это показывает, что запрос выполняет поиск индекса по созданному вами индексу IX_Orders_Country_Total, а не по индексу первичного ключа всей таблицы, как раньше.
Рекомендации по выявлению и устранению неполадок в медленных SQL-запросах
В этом разделе освещаются некоторые рекомендации по выявлению и устранению неполадок в медленных SQL-запросах, основанные на концепциях, представленных в этой статье.
Во-первых, регулярно контролируйте производительность ваших запросов с помощью таких инструментов, как view sys.dm_exec_query_stats для поиска длительно выполняющихся запросов.
Во-вторых, при устранении неполадок в медленных запросах используйте инструкцию SET STATISTICS PROFILE ON для получения плана выполнения запроса. Изучите план выполнения, чтобы понять, как выполняется запрос, и выявить любые недостатки.
Кроме того, обновление статистики гарантирует, что оптимизатор запросов будет располагать точной информацией о распределении данных. Используйте правильные типы данных, чтобы обеспечить хранение данных с максимальной экономией места, и используйте запросы на основе наборов вместо курсоров, поскольку они часто более эффективны.
Наконец, как показано в примере с хранимой процедурой выше, используйте соответствующую стратегию индексирования для вашей рабочей нагрузки, чтобы гарантировать, что запросы могут эффективно использовать индексы и избежать полного сканирования таблицы. При внесении изменений для повышения производительности запроса обязательно протестируйте и подтвердите изменения, чтобы убедиться, что они возымели желаемый эффект.
Заключение
На производительность SQL-запроса может повлиять несколько факторов, включая структуру, распределение данных и статистику таблиц, доступные индексы и конфигурацию сервера.
Следуя рекомендациям и используя такие инструменты, как планы запросов, статистика выполнения и системные представления, вы можете выявлять и устранять узкие места производительности в ваших SQL-запросах, что приведет к более быстрой и эффективной работе с базой данных.
Редактор: AndreyEx