8 лучших крупных языковых моделей на 2024 год

В последние годы в области обработки естественного языка (NLP) наблюдается заметный всплеск развития больших языковых моделей (LLM). Благодаря достижениям в области глубокого обучения и прорывам в transformers, LLM преобразовали многие приложения NLP, включая чат-ботов и создание контента.
Сегодня мы поможем вам понять, какие магистерские программы влияют на НЛП сегодня мы рассмотрим 8 лучших магистерских программ, влияющих на НЛП, и как вы можете решить, с какой из них работать:
- GPT-4
- Google Gemini
- Llama 3
- Claude 3
- Phi-2
- Mistral 8x22b
- Vicuna
- OLMo
Но сначала давайте обсудим большие языковые модели для непосвященных.
Что такое большие языковые модели?
Large language model — это модель на основе трансформатора (разновидность нейронной сети), обученная на огромных объемах текстовых данных понимать и генерировать человекоподобный язык. LLM могут выполнять различные задачи NLP, такие как генерация текста, перевод, обобщение, анализ настроений и т.д. Некоторые модели выходят за рамки преобразования текста в текст и могут работать с мультимодальными данными и задачами.
Трансформатор — это сеть прямой связи, которая получает питание от механизма самоконтроля. Базовая модель на основе трансформатора, состоящая из кодера и декодера, показана ниже:
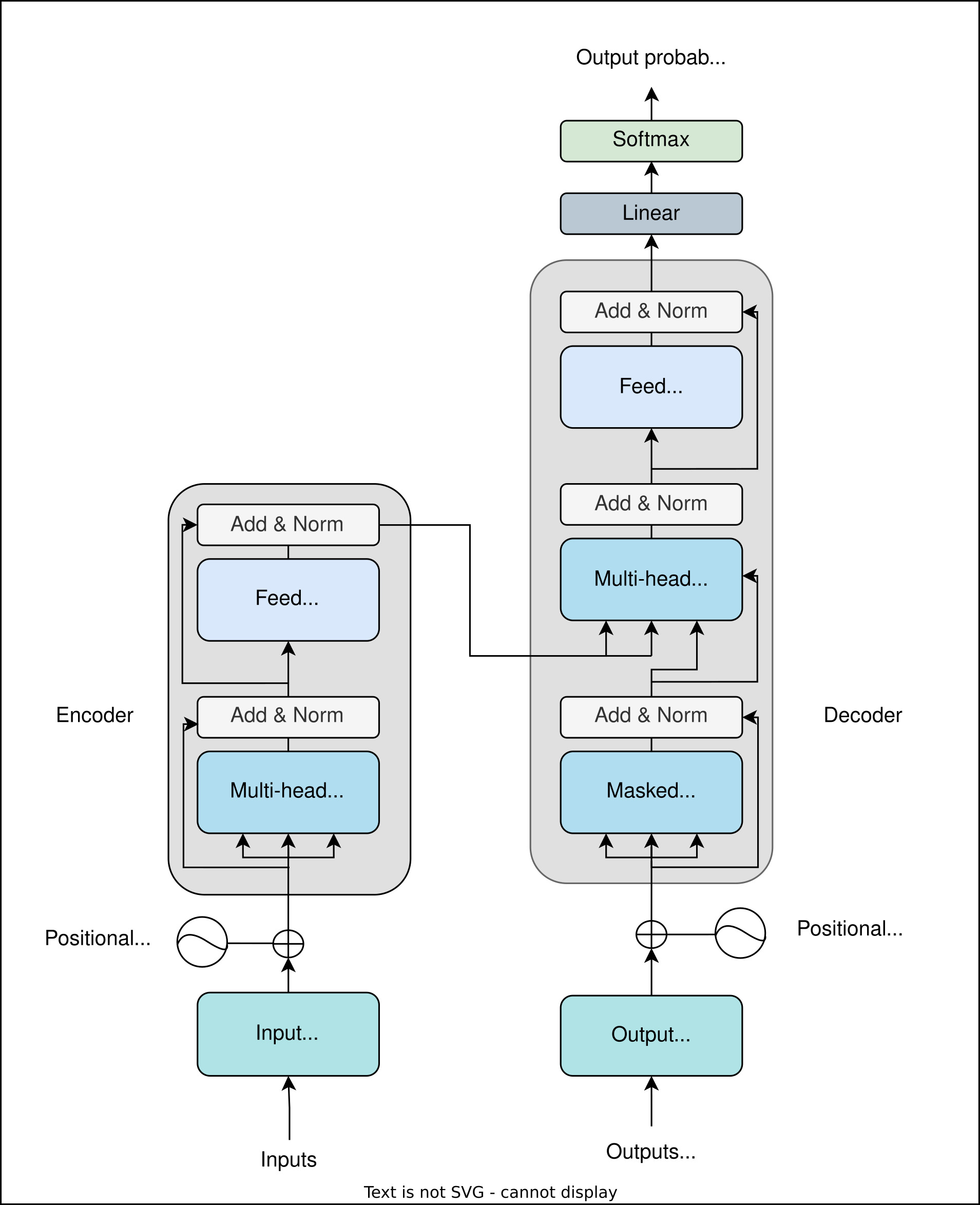
Архитектура vanilla transformer, где левая сторона представляет собой кодировщик, отвечающий за обработку входных данных, а правая сторона — декодер для генерации выходных данных
В такой модели кодировщик отвечает за обработку заданных входных данных, а декодер генерирует желаемый результат. Каждая сторона кодировщика и декодера состоит из стека нейронных сетей прямой связи. Самоконтроль с несколькими головками помогает трансформаторам сохранять контекст и генерировать релевантные выходные данные.
«Большой» в «большой языковой модели» относится к масштабу данных и параметров, используемых для обучения. Учебные наборы данных LLM содержат миллиарды слов и предложений из различных источников. Эти модели часто содержат миллионы или миллиарды параметров, что позволяет им улавливать сложные лингвистические закономерности и взаимосвязи.
Обучение магистров права начинается со сбора разнообразного набора данных из таких источников, как книги, статьи и веб-сайты, обеспечивая широкий охват тем для лучшего обобщения. После предварительной обработки выбирается подходящая модель, такая как transformer, из-за ее способности обрабатывать более длинные тексты с учетом контекста. Затем следует обучение и тонкая настройка. Этот итеративный процесс подготовки данных, обучения модели и точной настройки гарантирует, что LLM достигают высокой производительности в различных задачах обработки естественного языка.
8 лучших магистров права в 2024 году
Давайте рассмотрим эти 8 лучших языковых моделей, влияющих на НЛП в 2024 году, одну за другой.
1. GPT-4
GPT-4 — это мультимодальный LLM, разработанный OpenAI. Он принимает изображения и текст в качестве входных данных и выдает мультимодальный вывод. Это мощный магистр права, обученный на обширном и разнообразном наборе данных, что позволяет ему понимать различные темы, языки и диалекты. GPT-4 требует менее подробных инструкций по сравнению с GPT-3. GPT-4 имеет 1 триллион, в то время как GPT-3 имеет 175 миллиардов параметров, что позволяет ему обрабатывать более сложные задачи и генерировать более сложные ответы.
GPT-4 склонен генерировать неточную информацию, явление, которое часто называют «галлюцинирующими фактами». Для примера рассмотрим эту ошибку, когда GPT ответил Элвис Костелло , когда ответом был явно Элвис Пресли:
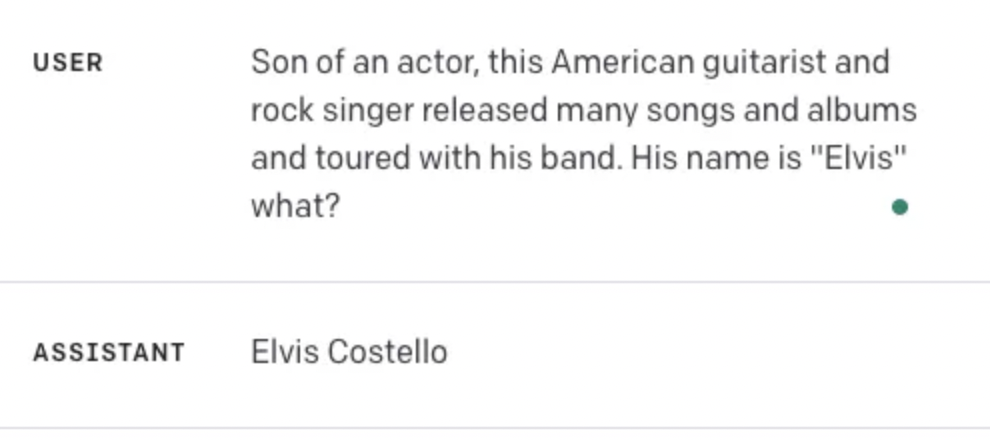
Тем не менее, галлюцинации присущи не только GPT-4, и сегодня он остается одним из самых популярных LLM.
2. Gemini
Gemini — это мультимодальный LLM, разработанный Google, который конкурирует с передовыми решениями других компаний в 30 из 32 тестов. Его возможности включают понимание изображений, аудио, видео и текста. Семейство Gemini включает версии Ultra (175 миллиардов параметров), Pro (50 миллиардов параметров) и Nano (10 миллиардов параметров), позволяющие решать различные сложные логические задачи в условиях ограниченного объема памяти на устройстве. Gemini может обрабатывать контекстные окна объемом до 32 тыс. токенов и построена с использованием архитектуры transformer с механизмом внимания к нескольким запросам. Они могут обрабатывать ввод текста, чередующийся с аудио- и визуальными вводами, и генерировать как текстовые, так и графические выходные данные.
Gemini работает лучше, чем GPT благодаря огромным вычислительным ресурсам Google и доступу к данным. Он также поддерживает ввод видео, тогда как возможности GPT ограничены текстом, изображением и звуком.
Давайте исследуем впечатляющие возможности кросс-модального мышления Gemini. На рисунке ниже показано приглашение, содержащее задачу по физике, нарисованную учителем (слева). В ответе (справа) подробно описано решение модели и объяснение

Gemini демонстрирует исключительные возможности
Как вы можете видеть, Gemini правильно проанализировала вопрос, выявила ошибки в решении студента и предоставила объяснение. Кроме того, она ответила на задачу по использованию LaTeX для математических компонентов. (1)
Этот курс раскрывает возможности Google Gemini, лучшей на сегодняшний день генеративной модели искусственного интеллекта Google. Это поможет вам глубоко погрузиться в возможности этой мощной языковой модели, исследуя ее возможности преобразования текста в текст, изображения в текст, текста в код и речи в текст. Курс начинается с ознакомления с языковыми моделями и тем, как работают унимодальные и мультимодальные модели. В нем рассказывается о том, как Gemini можно настроить через API и как работает Gemini chat, а также о некоторых важных методах подсказок. Далее вы узнаете, как различные возможности Gemini могут быть использованы в увлекательном интерактивном приложении для создания изображений в реальном мире. Наконец, вы познакомитесь с инструментами, предоставляемыми Google Vertex AI studio для использования Gemini и других моделей машинного обучения, а также улучшите приложение Pictionary с помощью функций преобразования речи в текст. Этот курс идеально подходит для разработчиков, специалистов по обработке данных и всех, кто хочет изучить преобразующий потенциал Google Gemini.
3. Llama 3
Llama 3 была разработана компанией Meta и основана на своих предшественниках, Llama 1 и 2. Это модель с открытым исходным кодом, которая превосходит контекстуальное понимание, перевод и генерацию диалогов.
В Llama 3 используется оптимизированная архитектура transformer с вниманием к сгруппированным запросам. Его словарь насчитывает 128 тыс. токенов, и он обучается на последовательностях из 8 тыс. токенов. Llama 3 (70 миллиардов параметров) превосходит Gemma и Mistral 7B instruct models по 5 бенчмаркам на уровне LLM.
Мультимодальные и многоязычные возможности все еще находятся в стадии разработки.
4. Claude 3
Claude 3 был разработан Anthropic и построен на своих предшественниках. Он имеет три версии:
- Haiku (~ 20 миллиардов параметров)
- Sonnet (~ 70 миллиардов параметров)
- Opus (~ 2 трлн параметров).
Пока что Claude Opus превосходит GPT-4 и другие модели во всех бенчмарках LLM.
Эти варианты моделей соответствуют политике оплаты за использование, но они очень мощные по сравнению с другими. Возможности Claude 3 включают расширенные рассуждения, анализ, прогнозирование, извлечение данных, базовую математику, создание контента, генерацию кода и перевод на неанглийские языки, такие как испанский, японский и французский.
5. Phi-2
Phi-2, разработанный Microsoft, имеет 2,7 миллиарда параметров. Технически он относится к классу малых языковых моделей (SLM), но его возможности рассуждения и понимания языка превосходят Mistral 7B, Llamas 2 и Gemini Nano 2 в различных тестах LLM. Однако из-за своего небольшого размера Phi-2 может генерировать неточный код и содержать предубеждения общества.
Phi-2 — это модель с открытым исходным кодом, поскольку она недавно приобрела лицензию MIT.
На следующем рисунке изображен Phi-2, точно решающий задачу, аналогичную физической задаче, которую мы видели в примере Gemini.

Phi-2 решает численную задачу по физике
6. Mixtral 8x22b
Mixtral 8x22b — это модель sparse mixture of experts (SMoE), разработанная компанией Mistral AI. Это модель с открытым исходным кодом, которая использует только 39B параметров из 141B. Возможности Mixtral включают в себя:
- Свободное владение английским, французским, итальянским, немецким и испанским языками
- Сильные математические способности и возможности программирования
- Вызов собственной функции
- Контекстное окно токена 64K для точного извлечения информации из больших документов
По сравнению с другими моделями, Mixtral превосходит GPT 3.5 и Llama 2 70B.
7. Vicuna
Vicuna — чат-бот, доработанный на основе модели LlaMA от Meta, разработанный для обеспечения мощных возможностей обработки естественного языка. Его возможности включают задачи обработки естественного языка, включая генерацию текста, обобщение, ответы на вопросы и многое другое.
Vicuna обеспечивает около 90% качества ChatGPT, что делает его конкурентоспособной альтернативой. Это открытый исходный код, позволяющий сообществу получать доступ к модели, изменять ее и улучшать.
8. OLMo
Институт искусственного интеллекта Аллена (AI2) разработал модель открытого языка (OLMo). Единственной целью модели было предоставить полный доступ к данным, обучающему коду, моделям и оценочному коду для коллективного ускорения изучения языковых моделей.
OLMo обучается на базе набора данных Dolma, разработанного той же организацией, который также доступен для публичного использования.
Какую модель использовать?
У каждой модели есть свои сильные и слабые стороны, поэтому наилучший выбор будет зависеть от таких факторов, как ваши конкретные требования к приложению, доступные ресурсы и приоритеты, такие как эффективность, мультимодальные возможности, этические соображения или сотрудничество с сообществом.
Вот сравнительная таблица, которую следует принять во внимание:
Название модели
Параметры | Плюсы | Минусы | |
GPT-4 | 1T | Мультимодальные | Галлюцинация |
Gemini | 10B-175B | Более высокая производительность за счет огромных вычислительных ресурсов и доступа к данным | Иногда не удается выявить ошибки в коде |
Llama 3 | 8B-70B | Превосходен в понимании контекста, переводе и создании диалогов | Ресурсоемкие вычислительные требования |
Claude 3 | Хайку (~ 20 страниц), Сонет (~ 70 страниц) и Опус (~ 2 страницы) | Превосходит GPT-4 | Платно |
Phi 2 | 2.7B | Открытый исходный код | Неточная генерация кода, социальные предубеждения |
Mixtral | 39B | Превосходит GPT 3.5 и Llama 2 multimodal | Ресурсоемкие вычислительные требования |
Vicuna | 13B | Обеспечивает около 90% качества ChatGPT с открытым исходным кодом | Производительность зависит от вариантов использования |
OLMo | 7B | Средство для решения проблем с кодированием | Ресурсоемкие вычислительные требования |
Мы надеемся, что этот обзор помог вам ознакомиться с ландшафтом LLM.
Редактор: AndreyEx




