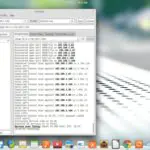
Grep с номером строки в выводе

Печать глобального регулярного выражения (Grep) — это универсальная утилита, которая выполняет поиск в системе обычного текста с помощью различных регулярных выражений. С помощью команды Grep мы можем выполнять множество операций; мы можем исследовать файлы, отображать номер строки в качестве вывода, игнорировать пробелы и рекурсивно использовать Grep. Grep с номером строки отображает номер строки соответствующего текста, присутствующего в файле. Эта функция выполняется с помощью –n. Со страницы Grep мы легко можем описать разные команды.
$ man grep
Предварительное условие
Чтобы достичь этой текущей цели получения определенного номера строки текста, у нас должна быть система для запуска команд в ней, которая является операционной системой Linux. Linux установлен и настроен на виртуальной машине. После ввода имени пользователя и пароля вы сможете получить доступ к приложениям.
Номер строки для сопоставления слова
Обычно, когда мы используем команду Grep, после ключевого слова Grep пишется слово, которое необходимо изучить, и за ним следует имя файла. Но, получив номер строки, мы добавим -n в нашу команду.
$ grep –n is file22.txt
Вот слово, которое нужно исследовать. Номер начальной строки показывает, что связанный файл содержит слово в разных строках; в каждой строке есть выделенное слово, которое показывает строку, совпадающую с релевантным поиском.
Номер строки всего текста в файле
Номер каждой строки в файле отображается с помощью определенной команды. Он не только показывает текст, но и закрывает пустые места, а также упоминает их номера строк. Цифры показаны в левой части вывода.
$ nl fileb.txt
Fileb.txt — это имя файла. Тогда как n для номеров строк, а l показывает только имя файла. В случае, если мы искали определенное слово в любом файле, будут показаны только имена файлов.
Параллельно с предыдущим примером здесь (за исключением свободного места) упоминаются специальные символы. Они также отображаются и читаются командой для отображения номера строки. В отличие от первого примера статьи, эта простая команда показывает номер строки именно так, как он присутствует в файле. Поскольку ограничений поиска нет, объявляется в команде.
Показать только номер строки
Чтобы получить только номера строк данных в соответствующем файле, мы можем легко выполнить следующую команду.
$ grep –n command fileg.txt | cut –d: -f1
Первая половина команды перед оператором понятна, потому что мы обсуждали ранее в этой статье. Cut –d используется для вырезания команды, что означает подавление отображения текста в файлах.
Обеспечить вывод в одной строке
Следуя приведенной выше команде, вывод отображается в одной строке. Он удаляет лишнее пространство между двумя строками и показывает только номер строки, упомянутый в предыдущих командах.
$ grep –n command fileg.txt | cut –d:-f1 | tr “\n” “ “
Правая часть команды показывает, как отображается вывод. Вырезание используется для вырезания команды. В то время как второй «|» применяется для приведения к одной строке.
Показать номер строки строки в подкаталоге
Эта команда используется для демонстрации примера подкаталогов. Он будет искать слово «500» в файлах в данном каталоге.
$ grep –n 500 /etc/services
Этот пример хорош для определения вероятности возникновения ошибки в вашей системе путем проверки и сортировки определенных слов из каталога или подкаталога. /etc/ описывает путь к каталогу, в котором находится папка служб.
Показывать по слову в файле
Как уже было описано в примерах выше, это слово помогает искать текст внутри файлов или папок. Искомые слова будут записаны в кавычки. В самой левой части вывода упоминается номер строки, показывающий вхождение имени в той или иной строке в файле.
$ grep –n ‘AndreyEx’ fileme.txt
Вывод показывает всю строку в файле, а не только одно слово, присутствующее в строке, и выделяет только данное слово.
Bashrc
Это полезный пример получения номера строки в выводе. Это будет искать во всех каталогах, и нам не нужно указывать путь к каталогу. По умолчанию это реализовано во всех каталогах. Он показывает все выходные данные для файлов, присутствующих в подкаталогах, так как нам не нужно упоминать конкретное слово для поиска с помощью команды.
$ Cat –n .bashrc
Это расширение всех имеющихся папок. Указав имя расширения, мы можем показать соответствующие данные, то есть файлы с подробным описанием входа в систему.
Искать во всех файлах
Эта команда используется для поиска файла во всех файлах, содержащих эти данные. Файл * показывает, что он будет искать во всех файлах. Имя файла отображается с номером строки после имени в начале строки. Соответствующее слово выделяется, чтобы показать наличие слова в тексте файла.
$ grep –n my file*
Искать в расширениях файлов
В этом примере слово ищется во всех файлах с определенным расширением, то есть .txt. Каталог, указанный в команде, — это путь ко всем предоставленным файлам. Вывод также показывает путь в соответствии с расширением. Номер строки указывается после имен файлов.
$ grep –n my file*
Заключение
В этой статье мы узнали, как получить номер строки в выводе, применяя различные команды. Мы надеемся, что эти усилия помогут собрать достаточно информации по соответствующей теме.
Редактор: AndreyEx