MySQL против PostgreSQL: подробное сравнение

Выбор правильной системы управления базами данных (СУБД) является одним из первых важных решений в каждом новом программном проекте. MySQL и PostgreSQL — это проверенные варианты с отличной поддержкой функциональности и масштабируемостью. Они используются такими технологическими гигантами, как Facebook и Instagram, которые обслуживают миллионы пользователей по всему миру.
В то же время между MySQL и PostgreSQL существуют существенные различия. В этой статье мы рассмотрим эти различия и узнаем, как сделать осознанный выбор.
Основы систем управления базами данных
Система управления базами данных (СУБД) — это набор программного обеспечения, которое позволяет пользователям манипулировать данными, хранящимися в базе данных, или извлекать их. С помощью СУБД пользователи также могут изменять структуру данных или создавать функции для упрощения манипулирования данными.
Экземпляр
Экземпляр ссылается на текущее состояние базы данных в определенный момент времени. Сюда входят значения, хранящиеся в базе данных, существующие в ней таблицы и связи между таблицами.
Репликация
Репликация — это возможность копирования данных из первичной базы данных во вторичную базу данных, чтобы последняя могла служить резервной копией первой, когда это необходимо. Основная и вторичная базы данных будут регулярно синхронизироваться с помощью заданий cron или автоматически после каждого обновления базы данных, чтобы гарантировать, что вторичная база данных соответствует состоянию данных в первичной базе данных.
Раздел
Раздел в базе данных — это часть большой таблицы, которая была клонирована для повышения производительности при запросах данных из базы данных. Предполагается, что разделение должно происходить только в одном экземпляре базы данных.
Сегмент
Сегмент похож на раздел, поскольку он также является клонированной частью большой таблицы. Разница в том, что благодаря своему механизму сегментирование может выполняться в нескольких экземплярах базы данных, даже на нескольких компьютерах в разных регионах.
Техническое сравнение PostgreSQL против MySQL
PostgreSQL и MySQL — это системы управления базами данных, которые предлагают множество функциональных возможностей для решения широкого круга проблем. Приведенное ниже техническое сравнение должно помочь вам понять, чем они отличаются и какая из двух лучше подходит для вашего проекта.
Различия между PostgreSQL и MySQL
| Товары | PostgreSQL | MySQL |
|---|---|---|
| Тип СУБД | Объектно-ориентированная реляционная база данных | Реляционная база данных |
| Типы данных | Целые числа, текст, логические значения и типы данных, определенные клиентом | Поддерживает только определенные типы данных, а именно числовые, дату и время, строковые (символьные и байтовые), пространственные типы и JSON |
| Механизм хранения данных | Только zheap | InnoDB, MyISAM, Память, CSV, Архив и Blackhole |
| Схема | Базы данных могут содержать разные схемы | Схема и база данных — синонимы |
| Таблицы | Поддерживает наследование таблиц | Не поддерживает наследование |
| Языки | SQL, PL / pgSQL и C | Только SQL |
| Операторы-заказчики | Поддерживается | Не поддерживается |
| Иностранные таблицы | Поддерживается | Не поддерживается |
| Правила | Поддерживается | Не поддерживается |
PostgreSQL и MySQL оба
- Позволяет пользователям обновлять базовые данные из текущего представления
- Поддержка использования расширений для своих баз данных
- Поддержка создания пользовательских функций (наряду со встроенными) для выполнения вычислений и манипулирования данными в нескольких таблицах
- Поддержка каталогов
- Поддержка последовательностей в виде списка целых чисел, которые могут быть сгенерированы с помощью определенных команд
- Поддержка триггеров для определенных действий после обновления строки
- Поддержка полнотекстового поиска
- Поддержка преобразования данных
Тип СУБД
PostgreSQL — это объектно-ориентированная реляционная база данных, в то время как MySQL — это реляционная база данных. С PostgreSQL пользователи имеют поддержку объектов, классов и наследования, как и в объектно-ориентированных языках программирования.
Поддерживаемые типы данных
PostgreSQL поддерживает стандартные типы данных, такие как целые числа, текст, логические значения и типы данных, определенные клиентом.
MySQL поддерживает только определенные типы данных, а именно числовые, дату и время, строковые (символьные и байтовые) и пространственные типы, а также JSON.
Механизм хранения данных
PostgreSQL поддерживает только механизм хранения данных под названием zheap.
В MySQL у нас может быть несколько механизмов хранения на выбор. Механизмом хранения по умолчанию в MySQL является InnoDB. Также поддерживаются MyISAM, Memory, CSV, Archive и Blackhole.
Схема
В PostgreSQL каждая база данных может содержать разные схемы. Общедоступная схема будет создана автоматически, когда мы создадим новую базу данных в PostgreSQL. В случаях, когда в базе данных более 100 таблиц, создание нескольких различных схем для конкретных бизнес-требований может уберечь нас от перегрузки огромным количеством таблиц.
В MySQL схема и база данных аналогичны.
Таблицы
Таблицы в PostgreSQL наследуются, и всякий раз, когда мы создаем новую таблицу, также создается сопутствующий пользовательский тип данных.
MySQL не поддерживает наследование таблиц и пользовательские типы данных для них.
Число просмотров
Представления позволяют пользователям абстрагировать несколько таблиц в виде одной таблицы, чтобы мы могли легко запрашивать точные данные, которые нам нужны, из нескольких таблиц. MySQL и PostgreSQL позволяют пользователям обновлять базовые данные из текущего представления.
Расширения
Расширения позволяют пользователям упаковывать функции, таблицы, переменные данных и структуры данных в единый блок, который затем мы можем подключить к другому экземпляру базы данных или удалить целиком. И PostgreSQL, и MySQL поддерживают использование расширений для своих баз данных.
Функции
MySQL и PostgreSQL поддерживают создание пользовательских функций (наряду со встроенными) для выполнения вычислений и манипулирования данными в нескольких таблицах.
Языки
Поддержка нескольких языков обеспечивает пользователям гибкость при определении пользовательских функций. По умолчанию PostgreSQL поддерживает три языка: SQL, PL / pgSQL и C. Для других языков, таких как Python, Perl или Javascript, нам необходимо установить соответствующее расширение в базе данных PostgreSQL. Между тем, MySQL предлагает SQL только для создания функций.
Операторы
Операторы — это синтаксис для арифметических операций и для сравнения или логических операций. MySQL не поддерживает создание пользовательских операторов, но PostgreSQL поддерживает. Пользовательские операторы полезны при работе с пользовательскими типами данных.
Иностранные таблицы
Внешние таблицы — это виртуальные таблицы, которые могут ссылаться на другие источники данных, такие как CSV-файлы или базы данных NoSQL, такие как Redis или MongoDB. PostgreSQL поддерживает внешние таблицы для удобной интеграции с другими существующими форматами данных, в то время как MySQL этого не делает.
Каталоги
Каталог RDMS хранит информацию о системе баз данных, такую как ее таблицы, взаимосвязи между таблицами и ее метаданные в целом. И MySQL, и PostgreSQL поддерживают каталоги.
Последовательности
Последовательность — это список целых чисел, который может быть сгенерирован с помощью специальных команд, определенных RDMS. Мы можем ограничить количество целых чисел в последовательности ее минимальным и максимальным числами. Эта функция поддерживается как в PostgreSQL, так и в MySQL.
Правила
Правила используются для определения дальнейших действий, которые необходимо выполнить после применения определенной операции к конкретной таблице. Правило отличается от триггера.Триггеры вызываются после обновления любой строки, но правила могут быть вызваны только один раз после обновления нескольких строк. PostgreSQL поддерживает правила, тогда как MySQL — нет.
Триггеры
И MySQL, и PostgreSQL поддерживают триггеры, которые— как упоминалось выше, используются для вызова действия после обновления строки.
Полнотекстовый поиск
Полнотекстовый поиск позволяет пользователям находить соответствие всему слову в результатах поиска, а не определенному шаблону. И PostgreSQL, и MySQL поддерживают полнотекстовый поиск.
Преобразование данных
При работе с данными удобно иметь функцию, поддерживающую преобразование их из одного типа данных в другой. И MySQL, и PostgreSQL предлагают эту функцию.
Выбор СУБД для вашего проекта
Обе базы данных спроектированы так, чтобы быть масштабируемыми, поэтому они обе хорошо подходят для корпоративных проектов с большими объемами данных. Однако предположим, что проекту нужен эффективный способ хранения транзакционных данных (например, банковские проекты) или он содержит только пользовательские объектные типы данных вместо стандартных. В данном случае PostgreSQL является более подходящим выбором.
С другой стороны, MySQL больше подойдет для следующих сценариев:
- Проекту требуются различные механизмы хранения данных для поддержки различных вариантов использования.
- Проекту нужна легковесная база данных, чтобы ее можно было встраивать в небольшие устройства.
- Вам нужна только тестовая база данных для проекта.
Плюсы и минусы PostgreSQL и MySQL
Мы рассмотрели различия между PostgreSQL и MySQL, чтобы провести тщательное техническое сравнение и посмотреть, насколько они соответствуют вариантам использования программного обеспечения. Теперь давайте рассмотрим плюсы и минусы каждого из них.
PostgreSQL
PostgreSQL предоставляет множество функций, поддерживающих хранение данных и манипулирование ими, но также имеет некоторые недостатки.
Плюсы:
- Хотя PostgreSQL предлагает большой встроенный набор для начала, он также позволяет пользователям определять дополнительные типы данных
- PostgreSQL автоматически создаст типы любой определенной таблицы.
- Существует активное сообщество, предоставляющее расширения для настройки типов данных для повышения производительности PostgreSQL и соответствия бизнес-требованиям.
- Он может эффективно обрабатывать транзакции, что делает его подходящим для финансовых учреждений.
- PostgreSQL также может обрабатывать нереляционные данные.
- PostgreSQL разработан и реализован таким образом, чтобы соответствовать свойствам ACID (атомарность, согласованность, изоляция и долговечность), что делает его безопасной системой управления базами данных.
Плюсы:
- PostgreSQL не является легковесной СУБД. Типичный размер установки составляет более 100 МБ без расширений.
- У него более низкая производительность при чтении по сравнению с MySQL
MySQL
MySQL известен своей производительностью масштабирования и может быть легковесным для небольших приложений. Однако база данных по-прежнему имеет некоторые ограничения, такие как узкая поддержка типов данных.
Преимущества MySQL
- Он предлагает гибкость при выборе механизма хранения, который позволяет пользователям определять производительность, возможности и характеристики для экземпляров MySQL.
- Облегченный MySQL отлично подходит для встраиваемых приложений, хранилищ программного обеспечения для обработки данных, индексации контента или высокодоступных резервных систем в целом, во многом благодаря своей доступности и масштабируемости.
Недостатки MySQL
- Поддерживает стандартные типы данных.
- MySQL неэффективно работает со сложными запросами к базам данных с огромными объемами данных.
- Он не очень эффективно обрабатывает транзакции.
Реальные примеры использования
Самый простой способ понять, как MySQL и PostgreSQL используются в производственной среде, — это увидеть, как такой гигант, как Meta, использует эти две базы данных для обработки огромных рабочих нагрузок Facebook и Instagram, сохраняя при этом возможность масштабирования время от времени.
MySQL (Facebook )
Facebook использует MySQL для управления петабайтами данных, генерируемых их клиентами. Причина, по которой он выбрал MySQL для этой задачи, заключается в том, что он хорошо поддерживается для автоматизации и позволяет небольшим командам обрабатывать тысячи серверов баз данных.
Состояния экземпляра
В Facebook экземпляры MySQL имеют жизненный цикл. Экземпляр может находиться в разных состояниях, таких как рабочее, запасное, выделенное запасное, де-выделенное запасное, повторное использование или удаленное.
Нахождение в рабочем состоянии означает, что инстанс в данный момент запущен и обслуживает клиентов. В резервном состоянии инстанс находится в пуле и может быть использован в любое время. Выделенный резерв, отмененный резерв и повторное использование являются переходными состояниями в процессе обслуживания базы данных. Завершенное состояние — это когда аналитик базы данных исследует экземпляр базы данных для решения существующих проблем с продуктом или любых других технических проблем.
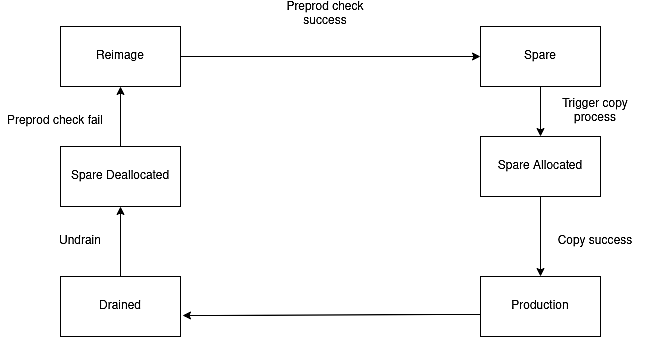
Рис. 1 : Жизненный цикл экземпляров MySQL
Обнаружение сервисов
Обнаружение сервисов имеет большое значение, особенно для таких организаций, как Facebook, у которых миллионы (или миллиарды) пользователей и для которых простои всего в несколько минут могут привести к значительным финансовым потерям. Обнаружение служб помогает справиться с катастрофическими проблемами, элегантно заменяя проблемный экземпляр базы данных новым, готовым к работе с производственными рабочими нагрузками.
Service discovery в Facebook имеет хэш-таблицу, хранящую идентификатор сегмента, набор реплик, master и slave экземпляров базы данных. Service discovery узнает о любых проблемах с этими экземплярами и быстро вызовет другой экземпляр для их замены. После этого обновления хэш-таблица будет обновлена новыми значениями.
| Идентификатор сегмента | Набор реплик | Мастер | Подчинение |
|---|---|---|---|
| 0–99 | Набор реплик 1 | db1.ms:3306 | db1.slav:3306 |
| 100–199 | Набор реплик 2 | db2.ms:3306 | db2.slav:3306 |
| 200–299 | Набор реплик 3 | db3.ms:3306 | db3.slav:3306 |
Таблица 1: Демонстрация хэш-таблицы обнаружения сервисов
Миграция для экземпляров MySQL
Миграция данных известна множеством проблем, с которыми сталкиваются разработчики программного обеспечения при внедрении радикальных изменений в производственную среду. Без надлежащих инструментов и методов программные продукты могут серьезно простоять. Теперь мы посмотрим, как Facebook обрабатывает миграцию для экземпляров MySQL.
Клонирование экземпляра
Это первый шаг в задаче переноса данных. Это также необходимо для перемещения данных из одного места в другое, балансировки использования базы данных или при работе со сломанными экземплярами базы данных.
MPS Copy
MPS Copy — это инструмент, разработанный Facebook для управления процессом клонирования экземпляров. Этапы процесса клонирования, которые охватывает MPS Copy, следующие:
- Выделение свободных мест: MPS Copy сначала выделит лучшую позицию для нового экземпляра, исходя из требуемого использования диска, загрузки процессора и домена сбоя.
- Настройка конфигурации MySQL: Будет запущен новый экземпляр с использованием соответствующей конфигурации, такой как выбор правильной версии RPM, генерация правильного my.cnf или загрузка правильного каталога.
- Копировать данные: Есть три способа сделать это. Они включают:
- Физическое копирование с использованием xtrabackup
- Физическая копия с использованием myrocks_hotbackup
- Логическое копирование с использованием mysqldump
- Репликация: Это может быть выполнено с текущего производственного главного узла или сервера Binlog
- Проверка: Это включает в себя использование механизма на основе контрольной суммы для проверки согласованности данных между новым реплицируемым экземпляром и старым главным узлом или сервером Binlog.
- Применение нового экземпляра: Новый экземпляр будет применен к производственной среде и будет готов обрабатывать трафик от пользователей.
- Удаление старого экземпляра: Когда новый экземпляр запускается без каких-либо проблем, мы можем безопасно удалить старый экземпляр.
Онлайн-миграция для shard
Онлайн-миграция (OLM) для shard помогает перемещать данные и особенно полезна, когда размер экземпляра базы данных превышает лимит уровня хоста и ему необходимо переместиться на другой хост. Ключевая концепция OLM заключается в перемещении данных из сегмента в другой экземпляр посредством локальной миграции, затем регистрации нового адреса сегмента в хэш-таблице service discovery.
Балансировка нагрузки
Реализация правильного выполнения балансировки нагрузки для MySQL помогает оптимизировать системные ресурсы.
Плохая укладка против правильной укладки
Допустим, есть четыре экземпляра данных, на которые приходится 1 ТБ рабочей нагрузки. Экземпляр 1 равен 400 ГБ; экземпляр 2 равен 200 ГБ, экземпляр 3 равен 100 ГБ, а экземпляр 4 равен 200 ГБ. Для хранения этих экземпляров доступно четыре хоста, емкость каждого из которых составляет 500 ГБ.
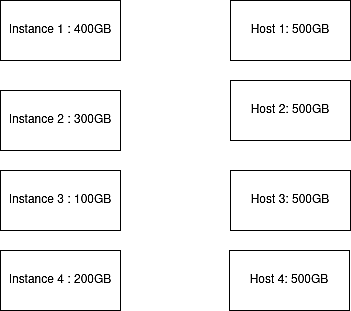
Рис. 2: Демонстрация инстансов и хостов перед выделением
Первый экземпляр будет размещен на хосте 1. Поскольку у хоста 1 нет необходимой емкости для экземпляра 2, после помещения экземпляра 1 на хост 1 экземпляр 2 будет отправлен на хост 2, как и экземпляр 3. Теперь на хосте 2 осталось всего 100 ГБ — этого недостаточно для экземпляра 4. Затем экземпляр 4 будет перемещен на хост 3.
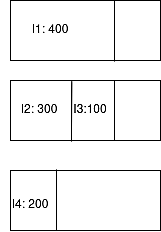
Рис. 3: Демонстрация плохой укладки
Сейчас мы используем три хоста для хранения этих четырех экземпляров, но есть лучший способ их хранения, позволяющий использовать системные ресурсы.
Вместо хранения экземпляра 4 на хосте 3 мы можем сохранить экземпляр 3 на хосте 1 и экземпляр 3 на хосте 2. При таком подходе для хранения экземпляров данных требуется всего два хоста.
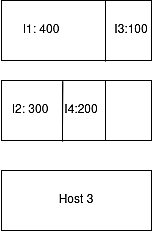
Рис. 4: Демонстрация правильного стекирования
Ключом к правильному стекированию является то, что перед назначением экземпляра хосту мы должны проверить наилучшее возможное место для размещения экземпляра.
Плохое формирование против правильного формирования
Чтобы немного по-другому взглянуть на приведенный выше случай, предположим, что время экземпляра базы данных 2 будет составлять 200 ГБ, а экземпляра 3 — 200 ГБ.
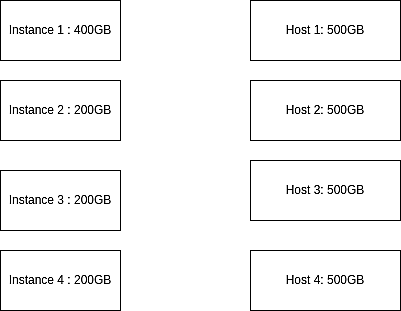
Рис. 5: Демонстрация инстансов и хостов перед выделением
Здесь экземпляр 1 будет отправлен на хост 1; экземпляр 2 и экземпляр 3 будут отправлены на хост 2. Тогда экземпляр 4 не сможет перейти на хост 1 или 2, поскольку у них недостаточно емкости, и вместо этого он будет размещен на хосте 3. В этом случае мы потратили хост 3 впустую на обработку только 200 ГБ данных.
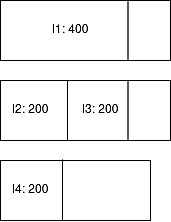
Рис. 6 : Демонстрация плохого шейпинга
Решение для оптимизации пропускной способности хоста здесь заключается в разделении рабочей нагрузки.
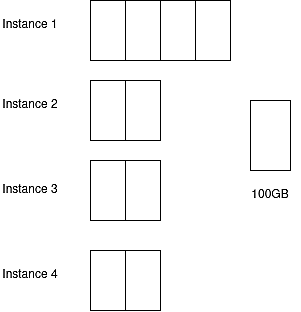
Рис. 7: Демонстрация разделения рабочей нагрузки в экземпляре базы данных
Затем мы можем переместить часть экземпляра 4 в экземпляр 2.
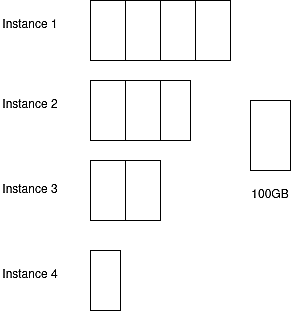
Рис. 8: Применение правильного шейпинга решает проблему
Проблема, которая у нас была с плохим формированием, теперь решена, и у нас осталась только проблема со стекированием — и мы уже обсуждали решение в предыдущем разделе.
PostgreSQL (Instagram)
Instagram использует PostgreSQL и несколько других систем управления базами данных, таких как Apache Cassandra или решения для кэширования баз данных, такие как Redis. Давайте посмотрим, как Instagram использует PostgreSQL и как они масштабируют экземпляры PostgreSQL для обработки огромных ежедневных рабочих нагрузок.
Сегментирование
Первое, что Instagram попытался сделать, чтобы увеличить нагрузку на пользователей в экземплярах базы данных PostgreSQL, было сегментирование их баз данных. Они рассматривали возможность использования других решений, таких как базы данных NoSQL, но в конце концов поняли, что разделение их экземпляров данных на меньшие сегменты будет работать лучше всего. Это решение подходит для рабочей нагрузки в 90 лайков в секунду, но когда она увеличится до 10 000 лайков в секунду, одного шардинга будет недостаточно.
Частичные индексы
До применения частичных индексов запрос тегов из небольшого числа строк в базах данных PostgreSQL занимал 215 мс.
EXPLAIN ANALYZE SELECT id from public.tags WHERE name LIKE 'snow%' ORDER BY media_count DESC LIMIT 10;
QUERY PLAN
---------
Limit (cost=1780.73..1780.75 rows=10 width=32) (actual time=215.211..215.228 rows=10 loops=1)
-> Sort (cost=1780.73..1819.36 rows=15455 width=32) (actual time=215.209..215.215 rows=10 loops=1)
Sort Key: media_count
Sort Method: top-N heapsort Memory: 25kB
-> Index Scan using tags_search on tags_tag
(cost=0.00..1446.75 rows=15455 width=32) (actual time=0.020..162.708 rows=64572 loops=1)
Index Cond: (((name)::text ~>=~ 'snow'::text) AND ((name)::text ~<~ 'snox'::text))
Filter: ((name)::text ~~ 'snow%'::text)
Total runtime: 215.275 ms
(8 rows)
В этом случае PostgreSQL пришлось перебрать почти 15 000 строк, чтобы запросить правильный результат. После применения частичного индекса необходимое время сократилось всего до 3 мс.
CREATE INDEX CONCURRENTLY on tags (name text_pattern_ops) WHERE media_count >= 100
EXPLAIN ANALYZE SELECT * from tags WHERE name LIKE 'snow%' AND media_count >= 100 ORDER BY media_count DESC LIMIT 10;
QUERY PLAN
Limit (cost=224.73..224.75 rows=10 width=32) (actual time=3.088..3.105 rows=10 loops=1)
-> Sort (cost=224.73..225.15 rows=169 width=32) (actual time=3.086..3.090 rows=10 loops=1)
Sort Key: media_count
Sort Method: top-N heapsort Memory: 25kB
-> Index Scan using tags_tag_name_idx on tags_tag (cost=0.00..221.07 rows=169 width=32) (actual time=0.021..2.360 rows=924 loops=1)
Index Cond: (((name)::text ~>=~ 'snow'::text) AND ((name)::text ~<~ 'snox'::text))
Filter: ((name)::text ~~ 'snow%'::text)
Total runtime: 3.137 ms
(8 rows)
На этот раз PostgreSQL нужно было просмотреть только 169 строк. Вот почему с частичным индексом это намного быстрее, чем без него.
Функциональные индексы
Функциональные индексы, такие как индексирующие строки, могут оказаться полезными при масштабировании экземпляров базы данных PostgreSQL для увеличения рабочих нагрузок. Например, с очень длинными токенами based64 создание индексаторов для этих строк неэффективно, и в итоге мы просто получим дублирующиеся данные. При использовании индексации функций размер индексации составляет лишь десятую часть от полного способа индексации.
CREATE INDEX CONCURRENTLY on tokens (substr(token), 0, 8)
Устранение фрагментации
Таблицы данных PostgreSQL могут быть фрагментированы на дисках из-за реализации с использованием модели многоверсионного параллелизма. Чтобы решить проблему, Instagram использовал pg_reorg для реструктуризации таблицы данных в пять шагов:
- Блокировка таблиц
- Создание временной таблицы для хранения изменений в реструктурированных таблицах
- Создание новой таблицы для упорядочения индексов
- Синхронизируйте изменения из временной таблицы в новую
- Замена старой таблицы новой таблицей
Архивирование и резервные копии
Instagram использовал WAL-E, инструмент, созданный Heroku для непрерывного архивирования файлов журналов PostgreSQL. Эта комбинация резервного копирования и использования WAL-E позволила Instagram быстро развернуть новую реплику для своей базы данных PostgreSQL или переключиться с основного узла на существующий дополнительный.
Режим автоматической фиксации
Instagram использовал psycopg2, драйвер python для PostgreSQL, в приложении Django. При включенном режиме автоматической фиксации psycopg2 не будет вызывать BEGIN / COMMIT для каждого запроса, а вместо этого будет иметь свою отдельную транзакцию.
connection.autocommit = True
Это приводит к снижению загрузки процессора системы и уменьшению количества запросов между серверами и базами данных.
Заключение
Найти единственную базу данных, соответствующую конкретным потребностям проекта, непросто — это требует досконального понимания требований к работе и технологических аспектов каждой рассматриваемой базы данных.
В этой статье мы рассмотрели преимущества и недостатки MySQL и PostgreSQL и рассмотрели, как две организации под эгидой Meta выбирали каждую из них в соответствии с их уникальными бизнес-потребностями и требованиями к масштабированию для роста. Мы надеемся, что эти примеры окажутся полезными при выборе базы данных для вашего следующего программного проекта.
Редактор: AndreyEx




