Топ-5 инструментов OCR с открытым исходным кодом для Linux в 2025 году

OCR расшифровывается как оптическое распознавание символов. Программное обеспечение такого типа предназначено для преобразования изображений, картинок или отсканированных документов в редактируемый текст с возможностью поиска.
С его помощью вам не придётся вручную набирать документы, так как они автоматически преобразуются в машиночитаемый текстовый формат, что в некоторых ситуациях очень удобно и позволяет сэкономить время и силы.
Если вы ищете простой в использовании, но мощный инструмент OCR, то для пользователей Linux доступны как бесплатные, так и коммерческие варианты — от библиотек Python до профессиональных SDK.
В этой статье вы найдёте лучшие программы с открытым исходным кодом, которые можно использовать для преобразования любых имеющихся у вас материалов, будь то фотография или отсканированная копия официального документа, в редактируемый текст.
1. Инструменты оптического распознавания символов в ONLYOFFICE Docs
Если вы часто работаете с документами, электронными таблицами, презентациями, диаграммами и PDF-файлами, ONLYOFFICE Docs (https://www.onlyoffice.com/office-suite.aspx) может стать для вас идеальным выбором, поскольку он сочетает в себе надёжные возможности оптического распознавания символов и функциональность полнофункционального офисного пакета с открытым исходным кодом.
Этот пакет, доступный в виде самостоятельного решения для серверов Linux и Windows, которое легко интегрируется в любую веб-платформу DMS, CMS или для обмена файлами и обеспечивает совместную работу в режиме реального времени, также включает бесплатное настольное приложение, основанное на том же движке и совместимое с любым дистрибутивом Linux.
В ONLYOFFICE Docs OCR работает двумя способами, так что вы можете выбрать наиболее удобный для вас. Во-первых, на встроенном рынке плагинов есть плагин OCR. Он не предустановлен и требует ручной установки, которая занимает всего несколько кликов.
После установки плагин OCR позволит вам распознавать текст на изображениях и фотографиях в форматах PNG и JPG и вставлять распознанный текст в документы для дальнейшего редактирования.
Плагин OCR для ONLYOFFICE основан на Tesseract.js, библиотеке JavaScript, созданной на основе механизма оптического распознавания символов Tesseract, и поддерживает более 60 языков.
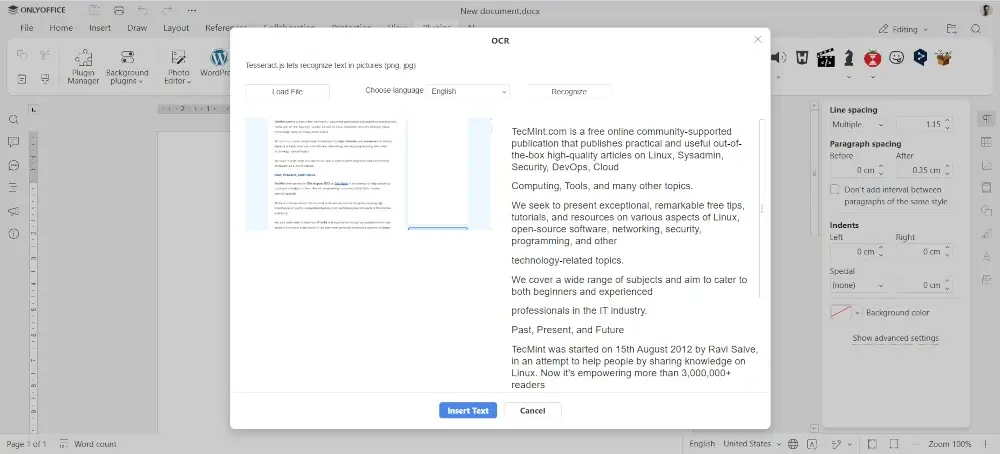
Плагин OCR для ONLYOFFICE
Другой способ использования OCR в ONLYOFFICE Docs предоставляет больше возможностей и функций, поскольку задействует искусственный интеллект. В пакете есть специальный плагин, основная цель которого — интегрировать все популярные ИИ-помощники и чат-боты и использовать их возможности для редактирования документов, например для генерации текста, перевода, исправления грамматики и стиля, обобщения и многого другого.
Некоторые современные модели искусственного интеллекта специально разработаны для распознавания текста, и вы даже можете найти некоторые LLM с открытым исходным кодом, предназначенные для оптического распознавания символов. Такие модели могут быть добавлены в плагин ONLYOFFICE AI при условии, что у вас есть действительный ключ API, выданный соответствующим поставщиком AI. После добавления ваша модель IA сможет распознавать текст по изображениям в вашем документе, используя опцию OCR в контекстном меню.
Самым большим преимуществом этой интеграции распознавания текста на базе искусственного интеллекта является то, что вам не нужно использовать что-то по умолчанию и вы можете преобразовывать изображения в редактируемый текст прямо в ваших документах. Вы вольны выбирать из различных моделей искусственного интеллекта, предоставляемых компаниями и платформами, которым вы можете доверять, например, Mistral, Anthropic, Ollama, GPT4ALL, LocalAI и другими, включая пользовательские модели.
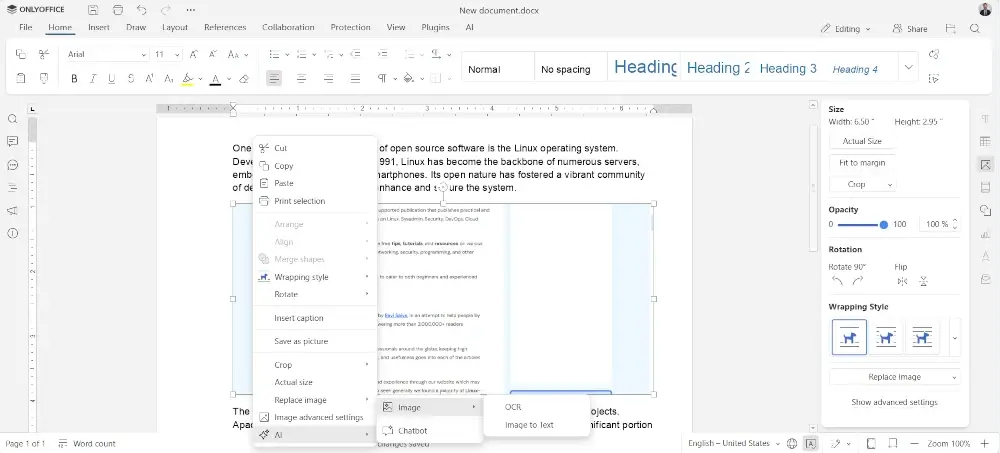
Плагин для искусственного интеллекта ONLYOFFICE
2. OCRmyPD
OCRmyPDF (https://github.com/ocrmypdf/OCRmyPDF) — это инструмент с открытым исходным кодом, который распознаёт текст, добавляя текстовый слой OCR на страницы PDF и делая их пригодными для поиска и операций копирования/вставки. На самом деле распознанный текст в ваших PDF-файлах нельзя редактировать, пока вы не откроете его в редакторе PDF.
OCRmyPDF добавляет новые слои текста с возможностью поиска в отсканированные PDF-файлы, сохраняя при этом исходные элементы форматирования PDF. Результатом преобразования OCR является новый PDF-файл с возможностью поиска и оптимизированными изображениями.
Инструмент использует механизм оптического распознавания символов Tesseract и легко справляется с файлами, содержащими тысячи страниц. Ещё одним преимуществом является то, что он обеспечивает конфиденциальность ваших данных, позволяя работать с конфиденциальными файлами и PDF-документами.
В качестве инструмента командной строки OCRmyPDF требует знания команд терминала, но позволяет автоматизировать процесс оптического распознавания символов.
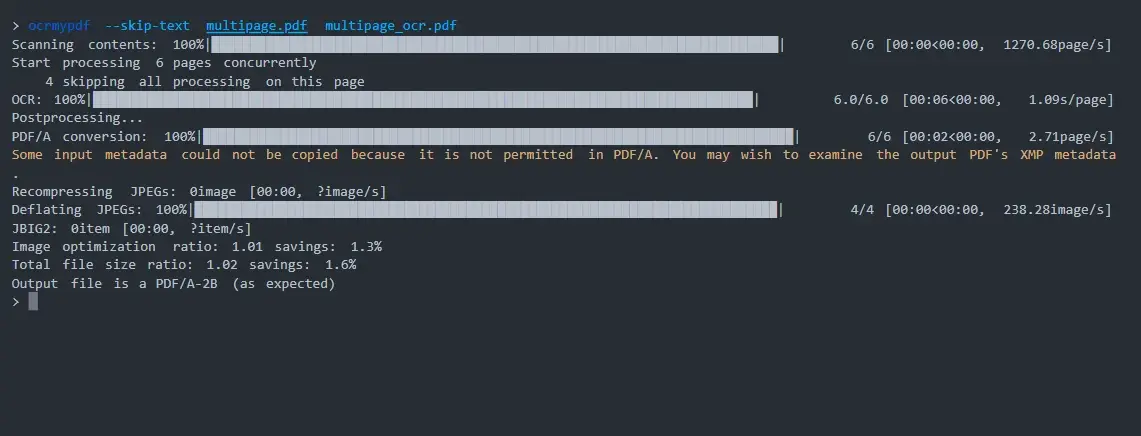
OCRmyPDF добавляет текстовый слой OCR к отсканированным PDF-файлам
3. gImageReader
gImageReader (https://github.com/manisandro/gImageReader) — бесплатная программа распознавания текста с открытым исходным кодом, разработанная как удобный интерфейс для движка Tesseract OCR. Благодаря интуитивно понятному графическому пользовательскому интерфейсу пользователи Linux могут без особых усилий извлекать текст из своих изображений, фотографий, отсканированных документов и PDF-файлов, что упрощает получение редактируемых текстовых форматов. При использовании этого инструмента вы можете вручную выбрать требуемую область распознавания или воспользоваться опцией автоматического выбора.
Одним из преимуществ gImageReader является возможность одновременной обработки нескольких файлов, что позволяет гораздо быстрее работать с большим количеством документов.
Помимо изображений и PDF-файлов, gImageReader также поддерживает hOCR — открытый стандарт представления данных для форматированного текста, полученного с помощью оптического распознавания символов. Например, вы можете конвертировать такие файлы в формат PDF.
Стоит также отметить многоязычную поддержку: помимо английского, gImageReader доступен на нескольких других языках.
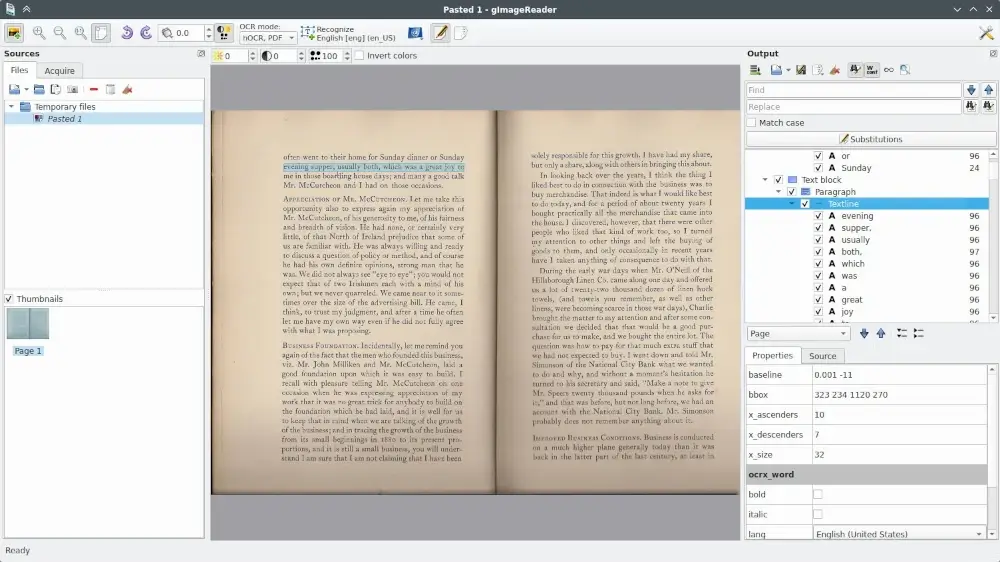
Используйте gImageReader для извлечения текста из изображений и PDF-файлов.
4. OCRFeeder
OCRFeeder (https://github.com/GNOME/ocrfeeder) — это набор инструментов распознавания текста с открытым исходным кодом для среды рабочего стола GNOME. Инструмент поставляется с графическим пользовательским интерфейсом, с помощью которого вы можете быстро исправлять нераспознанные символы в тексте, редактировать ограничивающие рамки, устанавливать стили абзацев и другие элементы, удалять входные изображения и выполнять все другие изменения вручную после завершения процесса распознавания.
С помощью OCRFeeder вы можете импортировать PDF-файлы и сохранять их в различных форматах после обработки, например в ODT или HTML. Когда вы открываете документ для оптического распознавания символов, программа автоматически выделяет его содержимое и с высокой точностью распознаёт текстовые символы.
Несмотря на графический интерфейс, OCRFeeder также поддерживает работу из командной строки и обеспечивает автоматическую пакетную обработку документов, что значительно экономит время и силы.
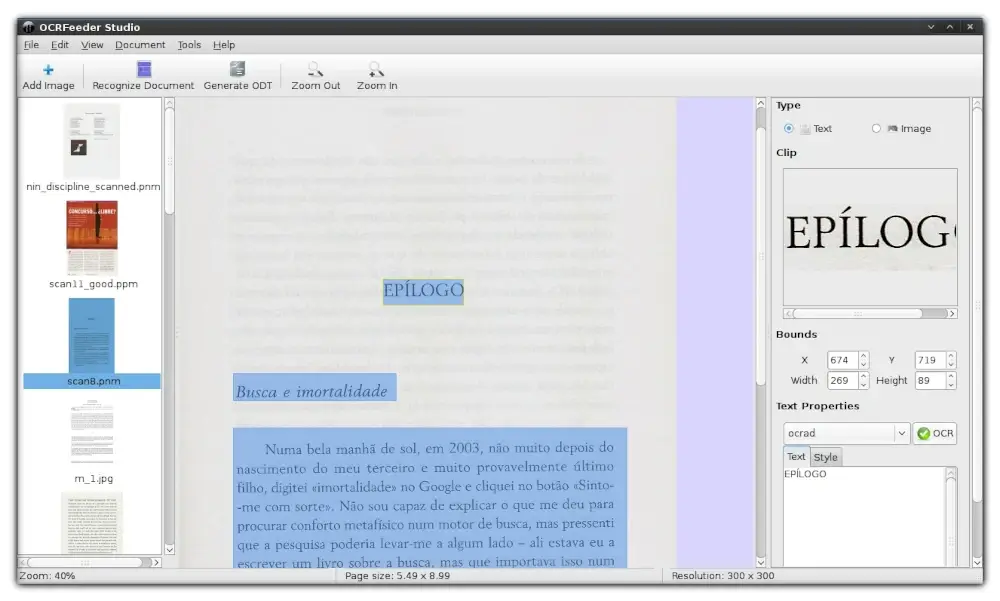
OCRFeeder — это набор инструментов для оптического распознавания символов в GNOME
5. Оформление документов
Paperwork (https://www.openpaper.work/en/) — это больше, чем просто приложение для оптического распознавания символов с открытым исходным кодом. Это полнофункциональная платформа для управления документами с возможностью ведения заметок. Основная идея этого программного обеспечения заключается в том, чтобы помочь пользователям Linux хранить, систематизировать и управлять всеми своими электронными документами в одном месте.
Если вы не хотите тратить много времени на сортировку и категоризацию документов, Paperwork — это то, что вам нужно. Благодаря принципу «отсканировал и забыл» вы можете отсканировать документ один раз и не вспоминать о нём, пока он вам снова не понадобится.
Приложение преобразует все ваши файлы в документы с возможностью поиска, чтобы вы могли быстро найти нужный документ, введя несколько слов. Вы также можете создавать метки и применять их к различным категориям в вашем хранилище файлов.
Paperwork легко интегрируется со сторонними сервисами, что позволяет подключить Nextcloud, Syncthing, SparkleShare или другие инструменты и создать централизованное хранилище для всех ваших файлов в разных папках.
Paperwork сканирует изображения и преобразует текст из них в редактируемый формат, позволяя вам выбирать, копировать и вставлять всё, что вам нужно.
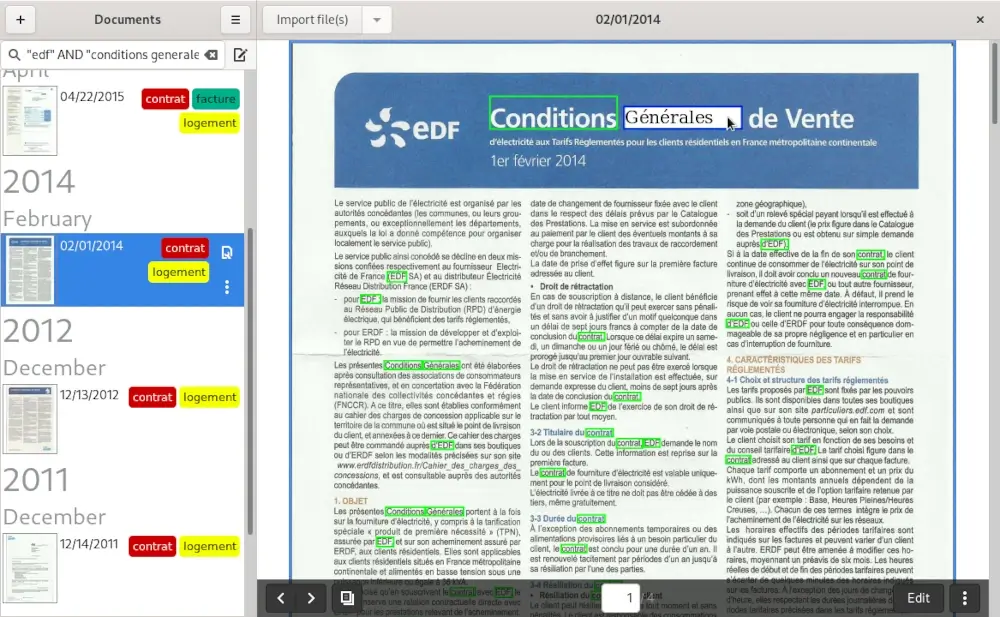
Paperwork — платформа для управления документами
Заключение
Хотя программное обеспечение для распознавания текста является нишевым, и не каждый пользователь Linux нуждается в нем на регулярной основе, такие программы очень помогают, когда вы хотите преобразовать скриншот или отсканированный PDF-файл в редактируемый текст. От инструментов командной строки до приложений с графическим интерфейсом — у вас есть достойный выбор для вашей операционной системы Linux.
Все перечисленные выше варианты имеют свои сильные и слабые стороны и лучше всего работают в определённых условиях. Однако все они имеют открытый исходный код и эффективно справляются с задачами оптического распознавания символов.
Редактор: AndreyEx
Важно: Данная статья носит информационный характер. Автор не несёт ответственности за возможные сбои или ошибки, возникшие при использовании описанного программного обеспечения.




