
Протокол сетевой файловой системы (NFS) помогает обеспечить локальный доступ к удаленным серверам NFS. По сути, он позволяет всем, у кого есть разрешения, получать доступ к файлам, как если бы они хранились на их локальном компьютере. С помощью NFS мы можем настраивать решения для централизованного хранения данных, и пользователи могут получать доступ к данным даже из удаленных мест. Более того, к NFS можно безопасно обращаться и управлять ею через брандмауэры и Kerberos (сетевой протокол, обеспечивающий аутентификацию клиент-серверных приложений с использованием криптографии с секретным ключом).
Для чего используется NFS?
NFS позволяет компьютерам — независимо от архитектуры или операционной системы — работать в одних и тех же файловых системах по сети. NFS можно запускать в разных операционных системах, поскольку она применяет абстрактную модель файловой системы вместо архитектурной спецификации.
При работе с NFS пользователи могут видеть все соответствующие файлы независимо от местоположения и работать с удаленными файлами так, как если бы они находились в их локальных файловых системах. Другие преимущества, предлагаемые NFS, включают:
- Обеспечение прозрачного монтирования файловых систем для пользователей
- Обеспечение согласованности и надежности данных за счет предоставления пользователям доступа к одним и тем же файловым системам
- Снижение затрат на хранение за счет совместного использования компьютерами хранилища данных вместо использования локального дискового пространства
Мониторинг производительности NFS
Чтобы убедиться, что производительность NFS соответствует нашим ожиданиям и что мы не испытываем непредвиденных проблем с производительностью, нам необходимо отслеживать производительность NFS. Мониторинг производительности NFS может потребовать большой работы— если реализован с нуля, поэтому лучше всего использовать существующие инструменты в экосистеме Linux. Есть два инструмента командной строки, которые могут помочь в мониторинге: nfsstat и nfsiostat.
С помощью команды nfsstat
Команда nfsstat отображает информацию о текущем запущенном сервере NFS в системе, а также выполненные удаленные вызовы процедур.
Например, если мы запускаем nfsstat -s на сервере, отображаемая информация о сервере NFS будет включать количество выполненных вызовов и наличие каких-либо ошибочных вызовов или неправильных проверок подлинности. Если на сервере NFS происходят какие-либо некорректные вызовы, скорее всего, сетевая система испытывает проблемы с задержкой в сети и ее необходимо проверить.
nfsstat -s

Рис. 1 : Информация о сервере NFS, полученная при запуске nfsstat -s
Мы также можем собирать информацию из клиента NFS, запустив:
nfsstat -c.
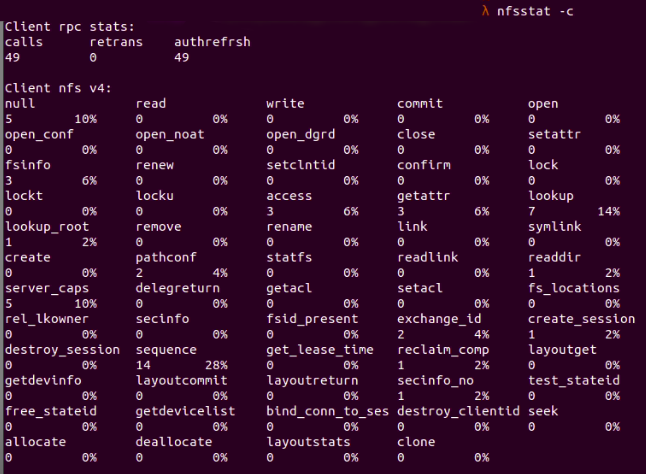
Рис. 2: Информация о клиенте NFS отображается при запуске nfsstat -c
Здесь мы видим, что клиент отправил 49 RPC-запросов, и ни один из них не был отклонен. RPC расшифровывается как удаленные вызовы процедур, и это позволяет процессу на одной машине вызывать подпрограмму на другой. RPC часто используется для создания распределенных клиент-серверных приложений.
Тем временем клиент отправил в общей сложности 49 запросов NFS, и ни один из этих запросов не был отклонен.
С помощью команды nfsiostat
Инструмент nfsiostat предоставляет нам полезную информацию о поведении системы NFS, считывая /proc/self/ mountstats в качестве входных значений, затем предоставляет запросы на чтение и запись подключенных общих ресурсов NFS.
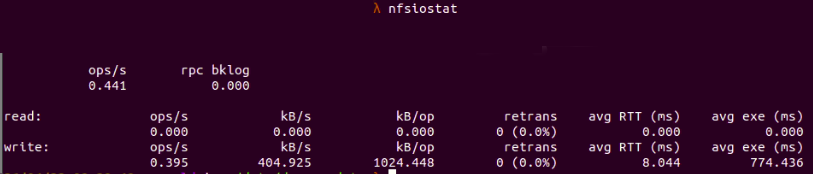
Рис. 3 : nfsiostat показана общая информация о клиенте NFS
Здесь мы можем увидеть папку монтирования в текущем клиенте NFS, которая
/mnt/donald_client_shared_folder
и целевой установки монтирования на сервере NFS, которая является
/mnt/donald_shares
Кроме того, на приведенном выше рисунке мы также можем увидеть подробные данные для запросов на чтение и запись к серверу NFS от клиента:
- op/s: количество операций, выполняемых в секунду (в данном случае 0,395 op/s для операций записи)
- rpc (bklog): длина очереди невыполненных работ (в данном случае отсутствует)
- kB/s: килобайт в секунду (404,925 кБ/с для операций записи здесь)
- kB/op: килобайт на операцию (1024,448 кБ/op для операций записи)
- retrans: количество повторных передач (в данном случае 0 повторных передач)
- avg RTT: среднее время с момента отправки клиентом RPC-запросов до получения ответа
- avg exe: среднее время с момента отправки клиентом RPC-запросов в ядро до завершения запросов
По умолчанию команда nfsiostat предоставляет результаты с момента подключения общего ресурса. Если данные должны приниматься за периодический интервал, счетчик должен быть предоставлен в качестве аргумента для командыnfsiostat.
В чем разница между iostat и nfsiostat?
Команда iostat предоставляет нам входные и выходные статистические данные для устройств хранения, чтобы мы имели представление о том, как эти устройства функционируют.

Как устранить неполадки с производительностью NFS
Чтобы эффективно диагностировать и устранять проблемы с производительностью NFS, выполните действия, описанные ниже.
Проверьте производительность сети
Сначала нам нужно проверить, есть ли в сетевой системе какие-либо проблемы с производительностью. Мы можем использовать несколько инструментов для мониторинга производительности сети, таких как команды vnstat и tcpdump.
vnstat это инструмент командной строки, который предлагает возможности мониторинга сетевого трафика для таких показателей, как потребление полосы пропускания и поток трафика. vnstat использует информацию ядра для создания журналов показателей.
tcpdump это инструмент сетевого анализа, который позволяет пользователям фиксировать и анализировать поток сетевого трафика в системе. tcpdump поддерживает фильтрацию значения сетевого трафика по IP, хосту, порту, протоколу или приложению.
Давайте посмотрим, как мы можем использовать tcpdump для проверки подробного сетевого пакета, который был отправлен или получен.
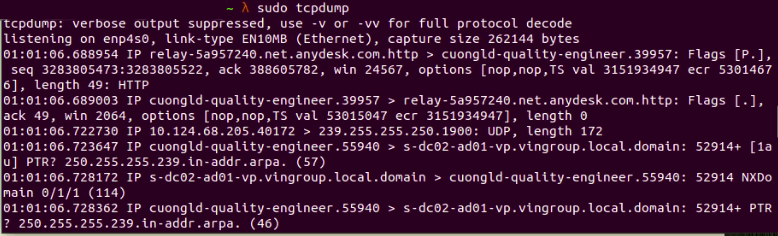
Рис. 4: tcpdump показаны переданные и принятые пакеты
Мы можем использовать vnstat для проверки наличия проблемы с производительностью сети путем измерения объема данных, проходящих через сетевой интерфейс.
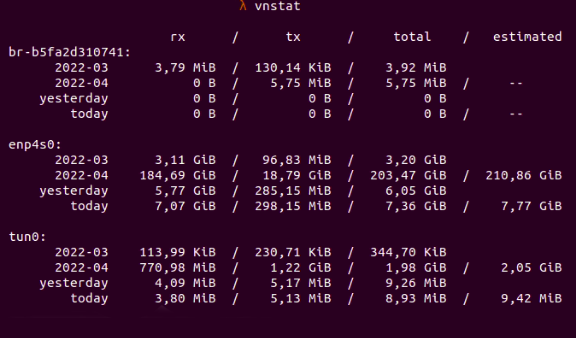
Рис. 5: Ввод и вывод данных при измерении с помощью vnstat
В приведенном выше сценарии для данных, прошедших через сетевой интерфейс enp4s0, мы имеем 7,07 ГБ полученных и 298,15 МБ переданных данных, при этом общий объем принятых и переданных данных составляет 7,36 ГБ.
Проверьте производительность сервера NFS
Если мы не обнаружим никаких проблем с производительностью сети, нам нужно посмотреть на производительность сервера NFS. Например, с помощью nfsstat -r мы можем найти количество вызовов RPC, выполненных на сервере. Если есть какие-либо ошибочные вызовы, отклоненные уровнем RPC, сеть, вероятно, перегружена, и нам нужно определить перегруженную сеть, просмотрев статистику для этого сетевого интерфейса.

Рис. 6 : nfsstat показаны вызовы RPC
Проверьте производительность клиента
Последнее, что нам нужно проверить, — это производительность NFS-клиента. Например, мы можем запустить nfsstat -c для проверки данных клиента NFS, таких как количество выполненных коммитов или записей или количество повторных передач для запросов RPC. Если количество повторных передач между клиентом и сервером велико, то либо сервер занят, либо произошла потеря в pocket. Количество повторных передач отображается как retrans в client rpc stats.
nfsstat -c
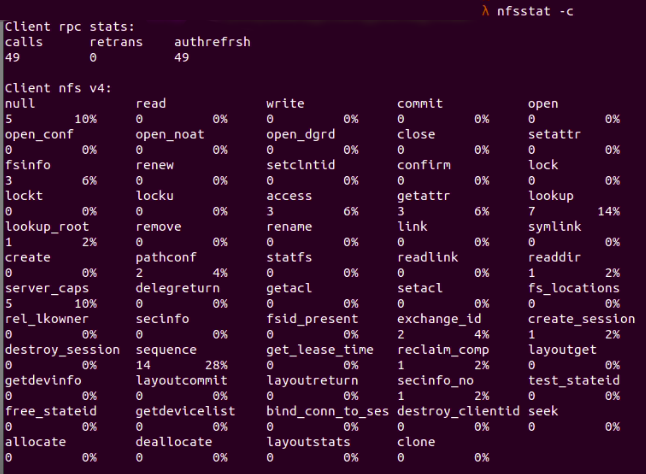
На рис. 7 : nfsstat -c подробно показаны данные клиента NFS
Кроме того, мы можем объединить это с nfsiostat -d для проверки статистики, связанной с каталогом сервера NFS:
nfsiostat -d
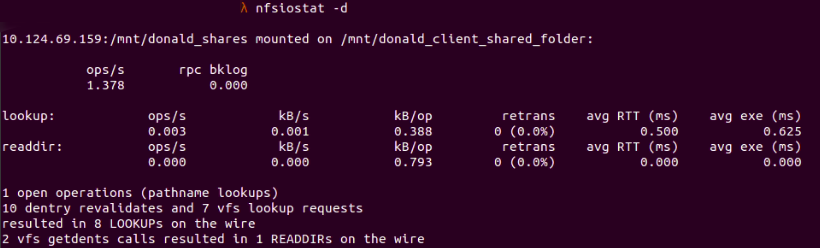
Рис. 8 : nfsiostat -d отображение статистики для каталога, который подключается к серверу NFS
Дальнейшие способы использования nfsiostat
Клиенты получат максимальную отдачу от систем NFS, поскольку они, скорее всего, специалисты по обработке данных или инженеры по обработке данных, использующие систему NFS для доступа к обширным данным для обучающих моделей. Если клиент не может устранить или локализовать проблему на своей стороне, сетевые администраторы могут инициировать устранение неполадок на стороне сервера.
Инструмент nfsiostat отлично подходит для обнаружения проблем на стороне клиента и предоставляет несколько вариантов сбора полезных показателей. Давайте рассмотрим несколько примеров его использования.
Проверьте общую статистику клиента NFS, запустив nfsiostat без параметров:
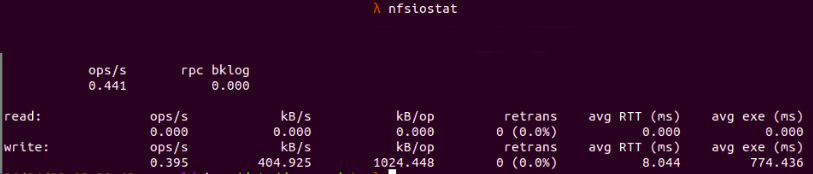
На рис. 9 : nfsiostat показана общая информация
Если мы подозреваем, что у клиента NFS возникают проблемы с производительностью при подключении к серверу NFS, нам следует обратить внимание на средние значения RTT и retrans. Высокое среднее время RTT и большое количество передач указывают на проблему с высокой задержкой в системе NFS, которая делает соединение между клиентом NFS и сервером нестабильным и приводит к проблемам с таймаутом.
Отображение статистики, связанной с кэшем, с помощью:
nfsiostat -a

Рис. 10: Отображение кэшированных данных с помощью nfsiostat -a
Недействительность кэша страниц показывает, сколько раз кэш на клиенте становился недействительным — в данном случае это 0. Недействительность кэша атрибутов показывает количество атрибутов в кэше, таких как время модификации или владелец — в данном случае у нас есть 3.
Применение кэширования предотвращает перегрузку сервера NFS запросами, отправляемыми от клиента NFS. Однако, если время кэширования велико, мы можем столкнуться с проблемой “Файл не найден”, когда клиент пытается прочитать файл на сервере, используя старые данные кэша, но файл на сервере уже обновлен до новой версии. Следовательно, мы должны настроить конфигурацию для применения кэширования соответствующим образом, чтобы соответствовать нашим собственным вариантам использования.
Отображение статистики, связанной с кэшем страницы, с помощью:
nfsiostat -p
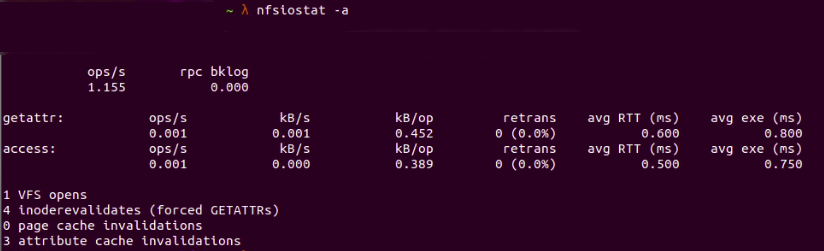
Рис. 11: Отображение кэша страниц с помощью nfsiostat -p
Сортировка точек подключения NFS по количеству операций в секунду с помощью запуска:
nfsiostat -s
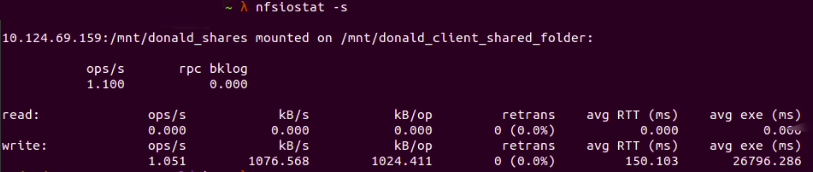
Рис. 12: Сортировка точек монтирования NFS с помощью nfsiostat -s
Выводите выходные данные с определенными интервалами через каждые $ {a} секунды и выводите данные $ {n} раз, выполняя nfsiostat ${a} ${n}:

Рис. 13: Запросы в NFS выполняются каждые 4 секунды и только 6 раз
Заключение
Существует множество факторов, которые могут прямо или косвенно вызывать проблемы с производительностью NFS. В этой статье мы рассмотрели несколько важных симптомов, указывающих на проблемы с производительностью в вашей системе NFS, и помогли вам определить их с помощью nfsiostat инструмента в Linux.
Поддерживаемые инструменты, такие как nfsiostat, могут упростить устранение неполадок с производительностью NFS, в противном случае являющееся длительным и трудоемким процессом.