Как использовать команду ‘next’ с Awk в Linux

В этой статьи мы углубимся в команду next и посмотрим, как ее можно использовать для оптимизации выполнения вашего скрипта, поскольку эта команда особенно полезна для пропуска ненужных шагов при обработке ваших данных.
Что такое команда next?
Команда next в awk сообщает ему пропустить оставшиеся шаблоны и действия для текущей строки и перейти к следующей строке ввода. Это может помочь избежать выполнения избыточных или ненужных шагов, делая ваши скрипты более эффективными.
Пример 1: помечение товаров в зависимости от количества
Давайте начнем с практического примера, рассмотрев файл с именем food_list.txt со следующим содержимым.
Food List Items No Item_Name Price Quantity 1 Mangoes $3.45 5 2 Apples $2.45 25 3 Pineapples $4.45 55 4 Tomatoes $3.45 25 5 Onions $1.45 15 6 Bananas $3.45 30
Рассмотрите возможность запуска следующей команды, которая будет помечать продукты питания, количество которых меньше или равно 20, со знаком (*) в конце каждой строки:
awk '$4 <= 20 { printf "%s\t%s\n", $0,"*" ; } $4 > 20 { print $0 ;}' food_list.txt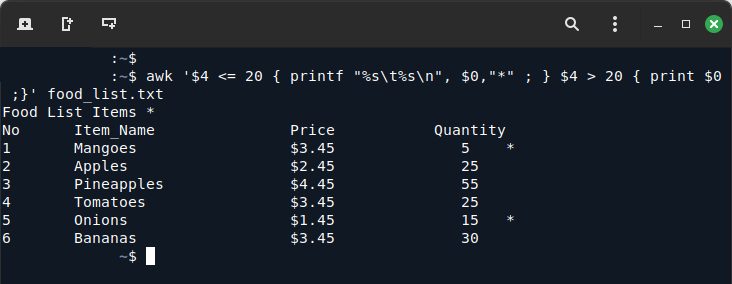 Помечаем элементы в зависимости от количества
Помечаем элементы в зависимости от количестваПриведенная выше команда на самом деле работает следующим образом:
- Сначала проверяется, является ли количество, четвертое поле каждой строки ввода, меньше или равно 20, если значение соответствует этому условию, оно печатается и помечается
(*)знаком в конце с использованием выражения one:$4 <= 20 - Во-вторых, она проверяет, больше ли четвертого поля каждой строки ввода, чем 20, и если строка соответствует условию, она печатается с использованием выражения two:
$4 > 20.
Проблема:
Но здесь есть одна проблема, когда выполняется первое выражение, строка, которую мы хотим пометить, печатается с помощью: { printf "%s\t%s\n", $0,"**" ; } а затем на том же шаге также проверяется второе выражение, что приводит к потере времени.
Таким образом, нет необходимости выполнять второе выражение $4 > 20 снова после печати уже отмеченных строк, которые были напечатаны с использованием первого выражения.
Оптимизированная команда с использованием next
Чтобы справиться с этой проблемой, вы должны использовать команду next следующим образом:
awk '$4 <= 20 { printf "%s\t%s\n", $0,"*" ; next; } $4 > 20 { print $0 ;}' food_list.txt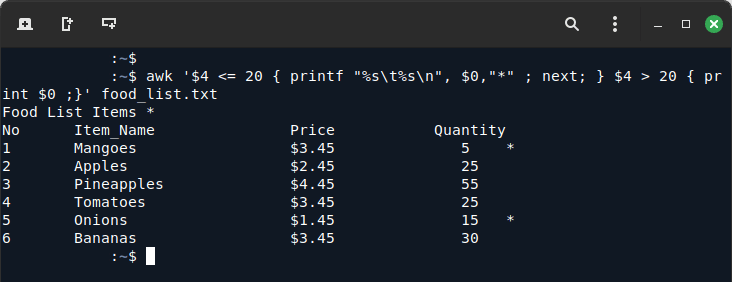 Оптимизированная команда с использованием next
Оптимизированная команда с использованием nextВот как это работает:
- Когда строка удовлетворяет условию
$4 <= 20, она выводит строку со звездочкой, а затем пропускает оставшиеся действия для этой строки, переходя непосредственно к следующей строке. - Это предотвращает проверку
$4 >l 20условия для уже обработанных строк.
Пример 2: Фильтрация и форматирование данных
Рассмотрим файл data.txt со следующим содержимым:
ID Name Age Score 1 Alice 30 85 2 Bob 25 90 3 Charlie 35 70 4 David 28 92
Если вы хотите печатать только записи с результатом выше 80 и форматировать их как “Name: [Name], Score: [Score]“, используйте:
awk '$4 > 80 { printf "Name: %s, Score: %d\n", $2, $4; next; }' data.txt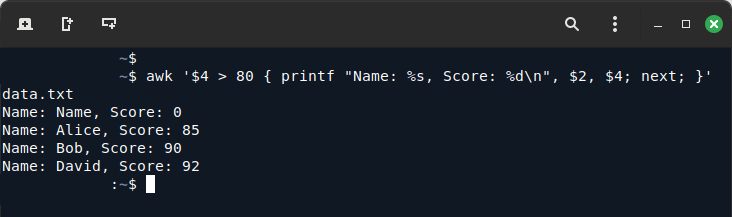
Выводы
Использование команды next в awk — это мощный способ оптимизировать обработку данных, избегая ненужных вычислений. Пропуская остальную часть скрипта для строк, которые уже были обработаны, вы делаете свои awk-скрипты более эффективными и быстрыми.
Редактор: AndreyEx




