
Работа с файлами PDF временами может быть довольно сложной задачей, поскольку они не очень изменяемы. Часто нужно извлечь несколько конкретных страниц из огромного документа, и это задание может показаться очень трудоемким. Именно поэтому мы посвятим эту статью тому, чтобы показать вам лучшие методы и лучшие инструменты, необходимые для извлечения страниц из файлов PDF в Linux.
Использование онлайн-инструмента
Файлы PDF стали одним из наиболее распространенных средств документирования и распространения данных. Из-за своей популярности многие веб-сайты и программы созданы специально для работы с этими файлами. Кстати, ILovePDF — это веб-сайт, полностью посвященный этой цели. В нем есть множество инструментов, которые вы можете бесплатно использовать для разделения, объединения, преобразования, организации, защиты и сжатия файлов PDF.
Поскольку мы хотим извлекать страницы из файлов PDF, мы будем использовать инструмент PDF Splitter, предлагаемый веб-сайтом, как указано выше. Когда у вас есть PDF-документ, из которого вы хотите извлечь страницы, нажмите здесь, чтобы перейти к онлайн-инструменту PDF Splitter.
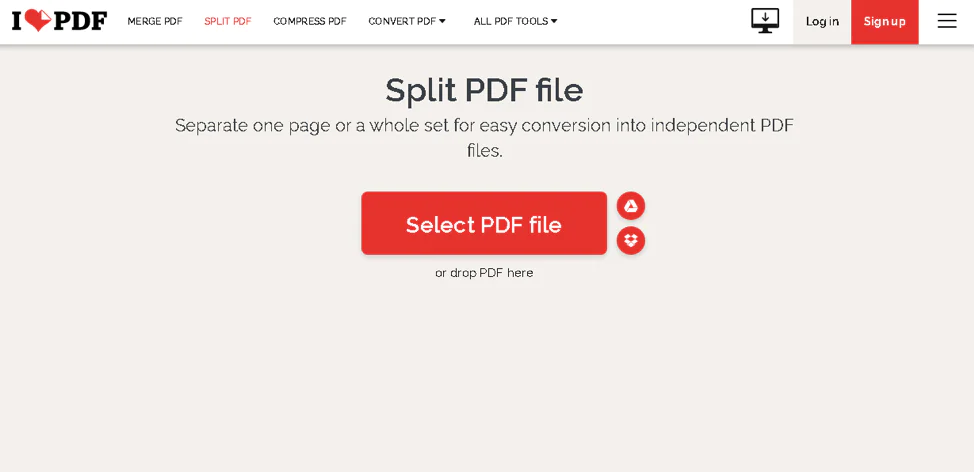
Нажмите кнопку Выбрать файл PDF и перейдите к своему документу. После того, как вы загрузили его, вы можете выбрать, хотите ли вы извлекать страницы или разбивать файл по диапазону.
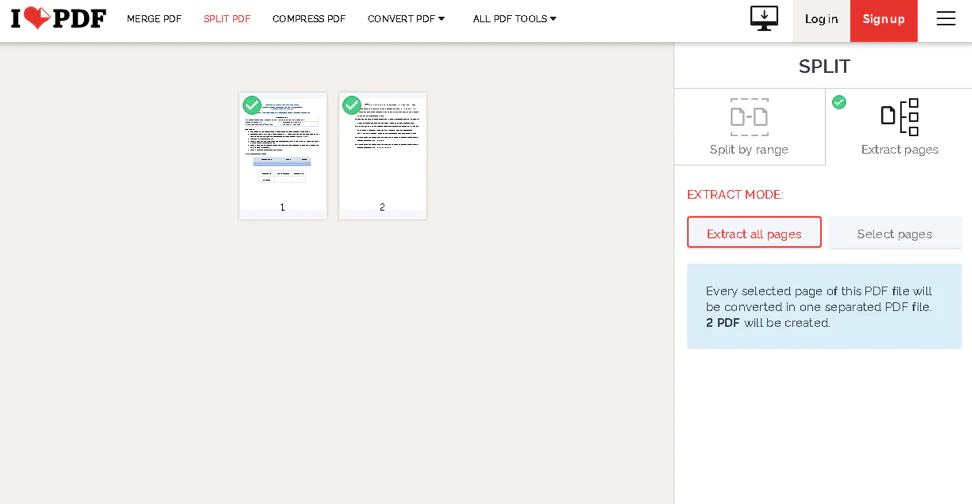
Идите вперед и выберите нужные параметры с помощью кнопок с правой стороны. Как только вы закончите, нажмите «Split PDF», и все готово. Он инициализирует загрузку файла .zip, который содержит извлеченные вами страницы.
ILovePDF также имеет бесплатное загружаемое приложение, но, к сожалению, оно доступно только для Windows и macOS. Однако это не умаляет его способности помогать вам извлекать страницы из PDF-файлов в Linux, поскольку вы также можете использовать его в Интернете. С учетом сказанного, теперь вы можете использовать совершенно бесплатный онлайн-инструмент для разделения PDF-файлов, чтобы выбирать определенные страницы из PDF-файлов и извлекать их без каких-либо проблем!
Использование PDFShuffler
Если по какой-либо причине — может быть, из-за проблем с конфиденциальностью или отсутствия функциональности — предыдущий метод вас не убедил, не беспокойтесь, так как у нас есть более благоприятные рекомендации, которые вы можете попробовать.
Одним из них является PDFShuffler, удобное приложение python-gtk, которое позволяет пользователям легко манипулировать файлами PDF. Его функции включают объединение, разделение, обрезку, поворот и изменение порядка файлов PDF. Этот инструмент дополняет свои обширные функциональные возможности за счет простого и интуитивно понятного графического интерфейса.
Вы можете щелкнуть здесь, чтобы загрузить PDFShuffler из Source Forge, или вы можете сделать это старомодным способом через командную строку. Перейдите в меню «Activities» или нажмите Ctrl + Alt + T на клавиатуре, чтобы открыть новое окно терминала.
Сделав это, выполните приведенные ниже команды для первой проверки обновлений, а затем установите PDFShuffler в вашу систему Linux. (Эти команды предназначены для Ubuntu 20.04, но другие версии не должны сильно отличаться от этих).
$ sudo apt update $ sudo apt install pdfshuffler
После завершения установки найдите недавно установленное программное обеспечение в меню «Activities» и запустите его. Экран по умолчанию должен выглядеть примерно так, как на изображении ниже.
Следующий шаг — ввести PDF-файл в программу, нажав кнопку «File» и выбрав опцию «Add» в раскрывающемся меню.
После этого настройте параметры извлечения и разделите файл. Результат должен дать вам желаемые извлеченные страницы из входного документа.
Использование PDFtk
Если вы особенно цените программы командной строки, а не программы с графическим интерфейсом, тогда PDFtk — это то, что вам нужно. Это эффективное решение с интерфейсом командной строки для пользователей, которым необходимо извлекать определенные страницы из файлов PDF. Давайте посмотрим, как вы можете установить его в различных дистрибутивах Linux и как его использовать.
Вернитесь в окно терминала или откройте новое и выполните следующие команды, если вы используете Ubuntu или Debian.
$ sudo apt install pdftk
Однако, если у вас не включен репозиторий universe, указанная выше команда не будет работать. Вы можете включить этот репозиторий, выполнив команду ниже.
$ sudo add-apt-repository universe
Сделав это, вернитесь к первой команде для установки PDFtk.
Если вы используете Arch Linux или один из его вариантов, выполните команду ниже. (PDFtk легко доступен через репозиторий сообщества).
$ pacman -S pdftk
Точно так же, если вы используете openSUSE, выполните приведенную ниже команду, чтобы установить PDFtk.
$ sudo zypper install pdftk
Наконец, если у вас включена привязка, вы также можете получить этот инструмент с помощью команды привязки.
$ sudo snap install pdftk
Далее давайте посмотрим на использование PDFtk. Как мы упоминали ранее, это инструмент командной строки, поэтому все, что вам нужно сделать, это запустить небольшую команду, чтобы получить то, что вам нужно.
$ pdftk input.pdf cat 3-4 output output_p3-4.pdf
Итак, что происходит в этой команде? Во-первых, input.pdf — это документ, который нужно разделить. Параметр 3-4 определяет диапазон номеров страниц от 3 до 4. Далее у нас есть имя выходного файла, которым является output_p3-4.pdf. Достаточно просто, и вы должны освоить его в кратчайшие сроки.
Однако, возможно, вам не нужно разбивать PDF-файл по диапазону номеров страниц; скорее, извлечение группы определенных страниц в отдельные файлы PDF. Не волнуйтесь, это можно сделать и с помощью этого инструмента. Все, что вам нужно сделать, это немного изменить команду, о которой мы упоминали ранее. Это изменение показано ниже.
$ pdftk input.pdf cat 3 4 output output.pdf
После этого вы можете разделить страницы 3 и 4 и сохранить их как output.pdf.
Вывод
В этой статье мы подробно рассказали, как извлекать страницы из файлов PDF. Мы рассмотрели удобный онлайн-инструмент, затем загружаемую программу на основе графического интерфейса пользователя и, наконец, решение для командной строки. Упомянутые выше инструменты богаты функциями и должны легко выполнять свою работу.