Рекомендации по созданию хранимых процедур в SQL

Язык структурированных запросов (SQL) — один из наиболее известных языков управления базами данных, предлагающий большую гибкость опытному разработчику. Хранимые процедуры являются одним из компонентов, повышающих эффективность, возможность повторного использования и безопасность управления базами данных.
Хранимая процедура — это группа инструкций SQL, которые создаются и хранятся в системе управления базами данных, позволяя нескольким пользователям и программам совместно использовать процедуру. Хранимая процедура может принимать входные параметры, выполнять определенные операции и возвращать несколько выходных значений. Это позволяет пользователям предоставлять различные входные данные для манипулирования или извлечения определенных частей данных. Затем, когда один пользователь изменяет хранимую процедуру, все пользователи получат это обновление. Большинство реляционных баз данных, таких как MySQL и SQL Server, поддерживают хранимые процедуры.
В этой практической статье рассматривается, как создать хранимую процедуру в SQL, и освещаются лучшие практики.
Преимущества использования хранимых процедур
Рассмотрим ситуацию, когда у вас есть один или несколько запросов, которые должны выполняться несколько раз с регулярными интервалами. Эти запросы должны выполняться вместе со сложной логикой в вашем приложении, чтобы применить бизнес-логику к данным. Этот процесс требует извлечения данных из базы данных, применения бизнес-логики для изменения данных и обновления базы данных.
К счастью, хранимые процедуры позволяют расширить функциональность базы данных за счет написания блоков кода для обработки данных. Затем вы можете вызвать базу данных для выполнения хранимой процедуры, которая применяет бизнес-логику. Результатом является сокращение сетевого трафика и значительное повышение производительности приложения.
Еще одним преимуществом хранимых процедур является их повторное использование. Хранимая процедура хранится в базе данных, компилируется один раз и используется многократно, тогда как SQL-запрос к базе данных должен компилироваться каждый раз. Хранимые процедуры также повышают безопасность базы данных, позволяя вам ограничить безопасность, предоставляя пользователю доступ к указанной процедуре, а не ко всей базе данных. Кроме того, использование хранимых процедур скрывает базовые сведения о базе данных (например, имена таблиц), поскольку пользователь обращается к ней, используя имя хранимой процедуры.
Создание хранимой процедуры
В этом разделе вы узнаете, как создать базовую хранимую процедуру в SQL, и познакомитесь с некоторыми рекомендациями по ее использованию.
Приступая к работе
В этой статье вы будете использовать базу данных AdventureWorks. AdventureWorks — это образец базы данных для Microsoft SQL Server, которая поддерживает стандартные сценарии онлайн-обработки транзакций (OLTP) для фиктивной производственной компании под названием Adventure Works Cycles. Для продолжения загрузите и установите SQL Server 2019 и SQL Server Management Studio 18. Затем загрузите файл резервной копии OLTP под названием AdventureWorks2019.bak и следуйте инструкциям по восстановлению образца базы данных на вашем экземпляре SQL Server.
Теперь у вас должна быть такая база данных:
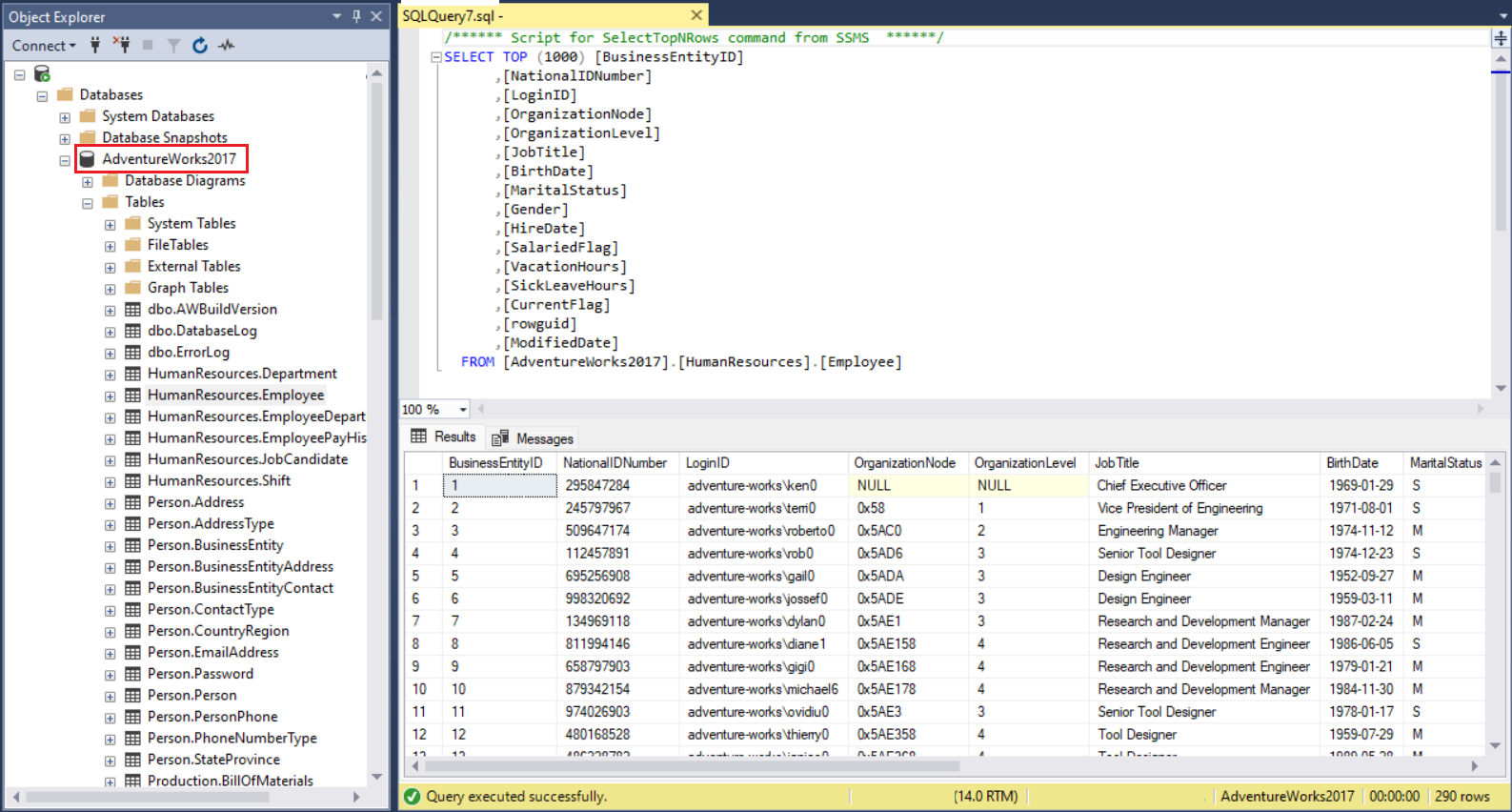
Рис. 1: База данных AdventureWorks.
Создание базовой хранимой процедуры в SQL
Для начала создайте новый запрос в SQL Server, нажав Новый запрос, или откройте новую вкладку запроса, нажав Ctrl + N.
Синтаксис для создания хранимой процедуры следующий:
CREATE PROCEDURE procedure_name AS BEGIN sql_statement END
Соответственно, чтобы создать процедуру, которая извлекает должности всех сотрудниц отдела кадров из HumanResources.В таблице Employee введите следующий сценарий:
CREATE PROCEDURE GetTitleForFemaleHREmployees ASBEGIN SELECT JobTitle FROM [AdventureWorks2017].[HumanResources].[Employee] WHERE Gender = 'F' END;
Затем нажмите F5, чтобы выполнить команду, которая компилирует и сохраняет хранимую процедуру.
Наконец, вызовите только что созданную процедуру, выполнив команду execute (EXEC):
EXEC GetTitleForFemaleHREmployees;
Чтобы запустить эту команду на той же вкладке запроса, выделите ее и нажмите Выполнить. В противном случае откройте новую вкладку запроса, чтобы запустить ее оттуда. Любой метод должен возвращать данные, изображенные ниже:
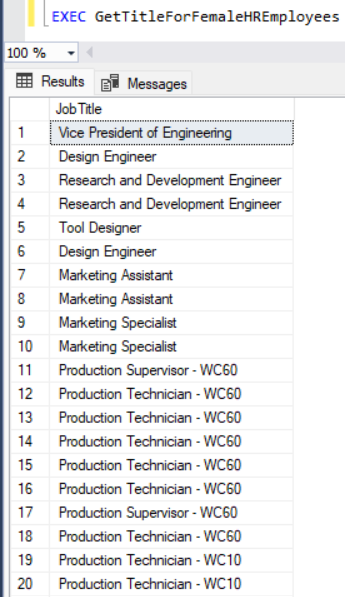
Рис.2: Результаты хранимой процедуры для получения названий должностей всех женщин-сотрудников отдела кадров.
В приведенном выше примере пол жестко запрограммирован в процедуре. Однако вы можете сделать ее более гибкой, разрешив пользователю указывать пол с помощью параметра. Вы также можете использовать параметры для возврата пользовательских данных вызывающему приложению.
Параметры используются для обмена данными между процедурой и приложением. Существует два типа параметров: входные и выходные. Входные параметры принимают данные от вызывающего приложения, а выходные параметры возвращают данные вызывающему приложению.
Параметры добавляются в виде аргументов, разделенных запятыми, после имени процедуры. Чтобы создать входной и выходной параметр, используйте следующий синтаксис соответственно:
parameter_name data_type, parameter_name data_type OUTPUT
Включение инструкции SELECT в тело хранимой процедуры вернет результаты вызывающему приложению. Однако вы можете использовать выходные параметры для возврата пользовательских данных.
Теперь пришло время улучшить предыдущий пример. Вы создадите процедуру для получения названий должностей всех сотрудников отдела кадров на основе пола, указанного во входном параметре, и вернете количество результатов. Используйте системную переменную @@ROWCOUNT, чтобы получить количество строк, прочитанных предыдущей инструкцией:
CREATE PROCEDURE GetTitleForHREmployees ( @Gender NCHAR(1), @EmployeeCount INT OUTPUT ) AS BEGIN SELECT JobTitle FROM [AdventureWorks2017].[HumanResources].[Employee] WHERE Gender = @Gender SELECT @EmployeeCount = @@ROWCOUNT; END;
Чтобы вызвать эту процедуру, объявите переменную @Count для получения выходного значения следующим образом
DECLARE @Count INT; EXEC GetTitleForHREmployees @Gender = 'F', @EmployeeCount = @Count OUTPUT; SELECT @Count AS 'Employee Count';
Результаты следующие:
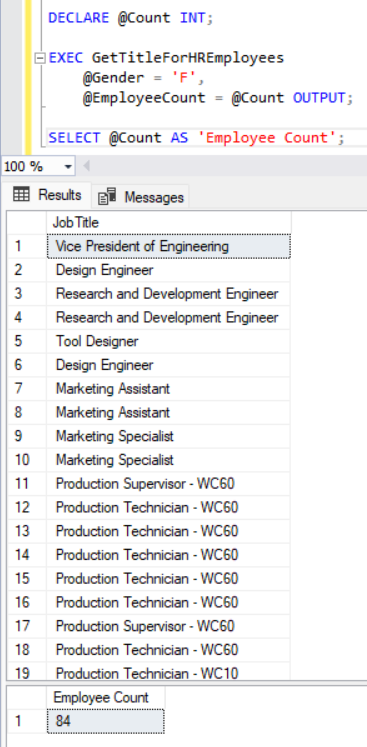
Рис. 3: Результаты хранимой процедуры с входными и выходными параметрами.
Также легко отфильтровать ваш запрос дальше, например, если вы хотите получить названия должностей всех сотрудников определенного пола, которые были наняты на определенное количество лет или меньше. Вы можете включить несколько параметров, добавив их в список аргументов, разделенных запятыми. Это позволяет вам создать процедуру для фильтрации по количеству отработанных лет и возврата максимального количества часов отпуска, которое взял один сотрудник из этого списка.:
CREATE PROCEDURE GetTitleForHREmployeesWithMaxVacation ( @Gender NCHAR(1), @NumberOfYearsHired INT, @EmployeeCount INT OUTPUT, @MaxVacation INT OUTPUT ) AS BEGIN SELECT JobTitle FROM [AdventureWorks2017].[HumanResources].[Employee] WHERE Gender = @Gender and DATEDIFF(YEAR, HireDate, GETDATE()) < @NumberOfYearsHired; SELECT @EmployeeCount = @@ROWCOUNT; SELECT @MaxVacation = MAX(VacationHours) FROM [AdventureWorks2017].[HumanResources].[Employee] WHERE Gender = @Gender and DATEDIFF(YEAR, HireDate, GETDATE()) <= @NumberOfYearsHired; END;
Вот результаты:
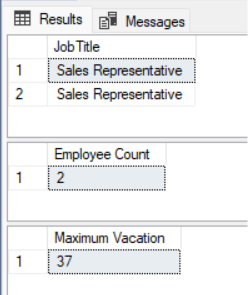
Рис. 4: Результаты хранимой процедуры с несколькими входными и выходными параметрами.
Рекомендации по созданию хранимых процедур
В предыдущем разделе вы узнали, как создавать базовые хранимые процедуры. Однако варианты использования хранимых процедур могут потребовать сложной логики. В этом разделе обсуждаются некоторые рекомендации, которым следует следовать при создании хранимых процедур.
Используйте SET NOCOUNT ON
Когда каждая инструкция выполняется в хранимой процедуре, SQL Server возвращает количество строк, на которые влияют результаты. Чтобы уменьшить сетевой трафик и повысить производительность, используйте SET NOCOUNT ON в начале хранимой процедуры. На рисунке ниже показаны результаты переключения NOCOUNT.
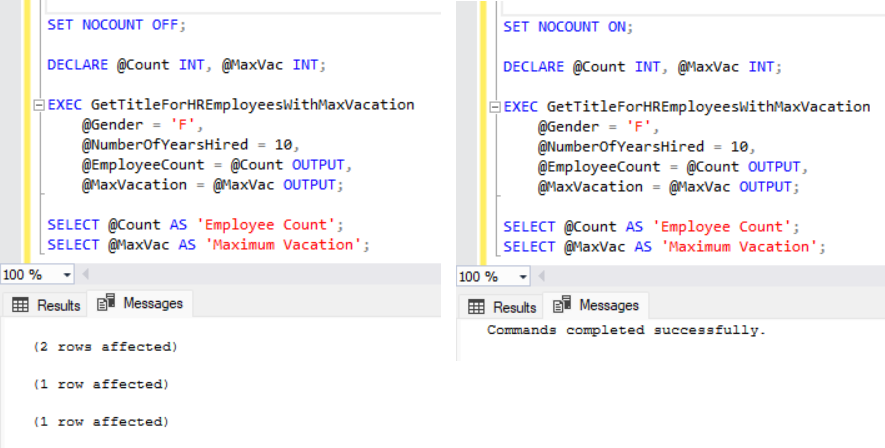
Рис. 5: Результаты установки NOCOUNT ON.
Поддерживайте порядок
Запросы должны быть разбиты на логические группы и инкапсулированы в блоки BEGIN / END. Кроме того, код должен иметь соответствующие отступы и достаточное количество комментариев.
Создайте временные таблицы в начале
Все инструкции языка определения данных (DDL) должны отображаться в начале. Инструкции DDL, такие как CREATE, ALTER, TRUNCATE и DROP, используются для создания схемы базы данных и определения типа и структуры данных, которые будут сохранены в базе данных. Временные таблицы должны создаваться в начале процедуры с использованием инструкций DDL.
Избегайте использования функций в объединениях
Не используйте функции в объединениях, потому что они вызовут проблемы с производительностью. Функция будет вызываться для каждой записи в результирующем наборе, и индексы для фильтруемых вами столбцов, которые окружены функцией, использоваться не будут. Вместо этого сохраните выходные данные функции во временной таблице и используйте временную таблицу при объединении.
Будьте осторожны с подзапросами
При написании хранимых процедур SQL подзапросы предлагают значительную полезность, но часто могут вызвать проблемы с производительностью и интерпретируемостью кода, особенно при работе с обширными наборами данных или сложной логикой. Предпочтительными альтернативами являются соединения SQL или временные таблицы, если это подходит. Однако имейте в виду, что многие современные системы баз данных способны эффективно оптимизировать подзапросы, а это означает, что они не всегда являются проблемой. При создании хранимых процедур целью должен быть баланс между эффективностью, простотой обслуживания и гибкостью.
Используйте согласованное именование
Всегда поддерживайте согласованную схему именования для всех объектов, столбцов и имен переменных.
Укажите префиксы схемы
Избегайте предположений о том, к какой схеме принадлежит таблица. Думайте о схеме как о пространстве имен. Если у вас есть объекты с похожими именами в разных схемах, их можно легко разрешить без каких-либо проблем, если вы укажете схему. Вы должны указывать схему, даже если у вас есть одна процедура, потому что, если вы добавите больше в будущем, вам придется обновлять свой код. Вот как мы указали схему в одном из примеров выше:

Рис. 6: Пример указания префикса схемы.
Заключение
В этой статье представлен краткий обзор того, что такое хранимые процедуры, продемонстрировано, как создать базовую хранимую процедуру, а также описаны преимущества и рекомендации по созданию хранимых процедур.
Хранимая процедура — это один из многих способов доступа к данным в базе данных, и она предлагает множество преимуществ. Использование хранимых процедур может значительно повысить производительность вашего приложения за счет сокращения сетевого трафика, устранения ненужной логики в вашем коде, а также изоляции и хранения соответствующей логики в базе данных.
Редактор: AndreyEx




