Оптимизация медленных SQL-запросов для больших наборов данных

Большие наборы данных могут представлять серьезную проблему для производительности SQL. По мере увеличения размера набора данных SQL-запросы становятся медленнее и менее эффективными. Ответы становятся вялыми, и производительность приложения снижается. Конечные пользователи разочаровываются, их производительность резко падает, а расходы на обслуживание баз данных растут.
При оптимизации SQL-запросов можно значительно повысить производительность приложения. В этой практической статье рассматриваются несколько методов повышения производительности запросов SQL Server для больших наборов данных.
Повышение производительности запросов SQL Server для больших наборов данных
Чтобы узнать, как повысить производительность запросов SQL Server к большим таблицам, вам сначала нужно создать dataset. Затем вам нужно будет идентифицировать, анализировать и оптимизировать медленно выполняемые запросы.
Предварительные требования
Чтобы завершить это руководство, убедитесь, что у вас есть следующее:
- Microsoft SQL Server
- Azure Data Studio (Mac) или Microsoft SQL Server Management Studio (Windows)
- База данных
Хотя в этом руководстве для выполнения всех примеров SQL-запросов используется Azure Data Studio, шаги те же, что и при использовании SQL Server Management Studio в Windows.
Шаг 1: Создайте большой набор данных
Во-первых, вам нужен большой набор данных, чтобы изучить все методы, описанные в этой статье. Используя приведенный ниже SQL-запрос, создайте таблицу продаж с миллионом строк случайно сгенерированных данных:
CREATE TABLE sales (
id INT IDENTITY(1,1),
customer_name VARCHAR(100),
product_name VARCHAR(100),
sale_amount DECIMAL(10,2),
sale_date DATE
sale_date DATE
)
DECLARE @i INT = 1
WHILE @i <= 1000000
BEGIN
INSERT INTO sales (customer_name, product_name, sale_amount, sale_date)
VALUES (CONCAT('Customer', @i), CONCAT('Product', FLOOR(RAND()*(10-1+1)+1)),
FLOOR(RAND()*(1000-100+1)+100), DATEADD(day, -FLOOR(RAND()*(365-1+1)+1), GETDATE()))
SET @i = @i + 1
ENDШаг 2: Определение медленно выполняющихся запросов
Как только у вас будет набор данных, пришло время оптимизировать SQL-запросы. Ваш первый шаг — определить медленно выполняющиеся запросы.
Вы можете использовать представление системного динамического управления sys.dm_exec_requests (DMV) в SQL для поиска этих запросов. Это представление предоставляет множество информации о запущенных запросах, включая состояние, время процессора и общее затраченное время. Мониторинг этих показателей помогает выявить медленные запросы.
Например, изучите следующий запрос, который извлекает имена клиентов и их общие суммы продаж за 2023 год из таблицы sales:
SELECT customer_name, SUM(sale_amount) AS total_sales FROM sales WHERE YEAR(sale_date) = 2023 GROUP BY customer_name
После запуска запроса используйте DMV sys.dm_exec_requests, чтобы просмотреть ход выполнения запроса:
SELECT r.session_id, r.status, r.total_elapsed_time, r.cpu_time, r.wait_time, r.command FROM sys.dm_exec_requests r CROSS APPLY sys.dm_exec_sql_text(r.sql_handle) WHERE status != 'sleeping'
Это действие возвращает список активных запросов на сервере с указанием их общего затраченного времени и времени процессора. Оцените эту статистику, чтобы определить, выполняется ли ваш запрос медленно.:
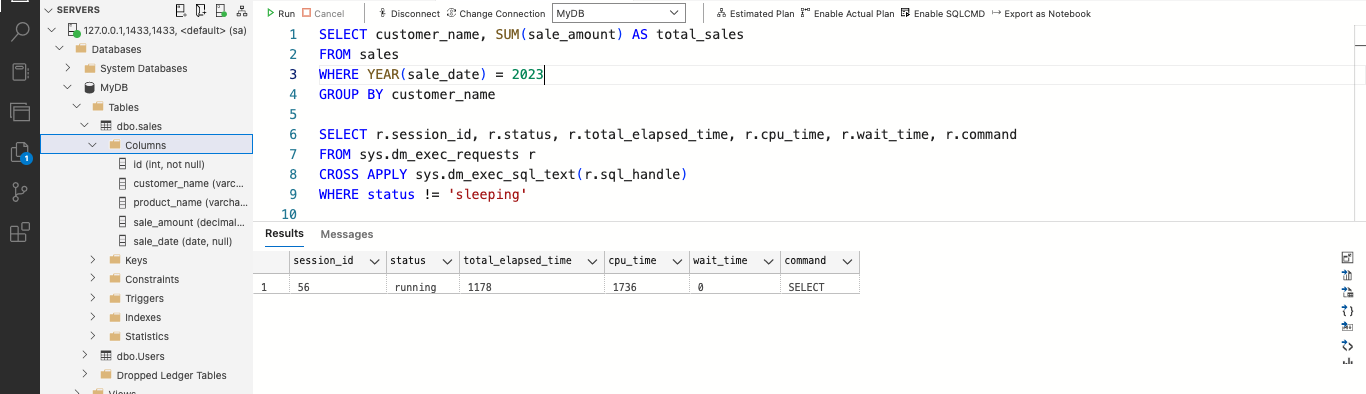
Рис. 1: Определение медленно выполняющихся SQL-запросов
Приведенный выше пример запроса возвращает статистику, такую как total_elapsed_time в 1178 миллисекунд и cpu_time в 1736 миллисекунд. Если для вашего конкретного приложения это время кажется необычно долгим, вы можете оптимизировать запрос, чтобы повысить его производительность.
Ожидание вместо запущенных запросов
SQL-запросы делятся на две категории: ожидающие и выполняемые. Понимание их различий имеет решающее значение для оптимизации производительности запросов.
Запущенный запрос активно использует системные ресурсы, включая процессор, память и дисковый ввод-вывод. Ожидающий запрос ожидает завершения другого запроса или получения системных ресурсов.
Выполняемые и ожидающие запросы могут влиять на производительность вашей базы данных. Ожидающие запросы могут блокировать другие запросы, замедляя выполнение запросов и время ответа. Оптимизация обоих типов запросов помогает повысить производительность SQL Server для больших наборов данных.
Шаг 3: Анализ и оптимизация медленно выполняемых запросов
Теперь, когда вы определили медленно выполняющиеся запросы, следующий шаг — улучшить их. Вы можете включить несколько рекомендаций в SQL-запросы, чтобы повысить их производительность на больших наборах данных.
Ограничение возвращаемых данных
Чтобы оптимизировать SQL-запросы при работе с большими наборами данных, рассмотрите возможность ограничения объема данных, возвращаемых этими запросами с помощью оконных функций или разбивки на страницы.
Оконные функции могут группировать, агрегировать и ограничивать данные из больших наборов данных. Например, таблица продаж может содержать миллион строк, и вы хотите отобразить 10 записей на странице. Используйте оконную функцию ROW_NUMBER() для присвоения номеров строк и фильтрации на основе нужной страницы, как в коде ниже:
DECLARE @page_number AS INT; SET @page_number = 2; WITH numbered_sales AS ( SELECT *, ROW_NUMBER() OVER(ORDER BY sale_date) AS row_num FROM sales ) SELECT * FROM numbered_sales WHERE row_num > 10 * (@page_number - 1) AND row_num <= 10 * @page_number
Этот код возвращает 10 записей на второй странице:
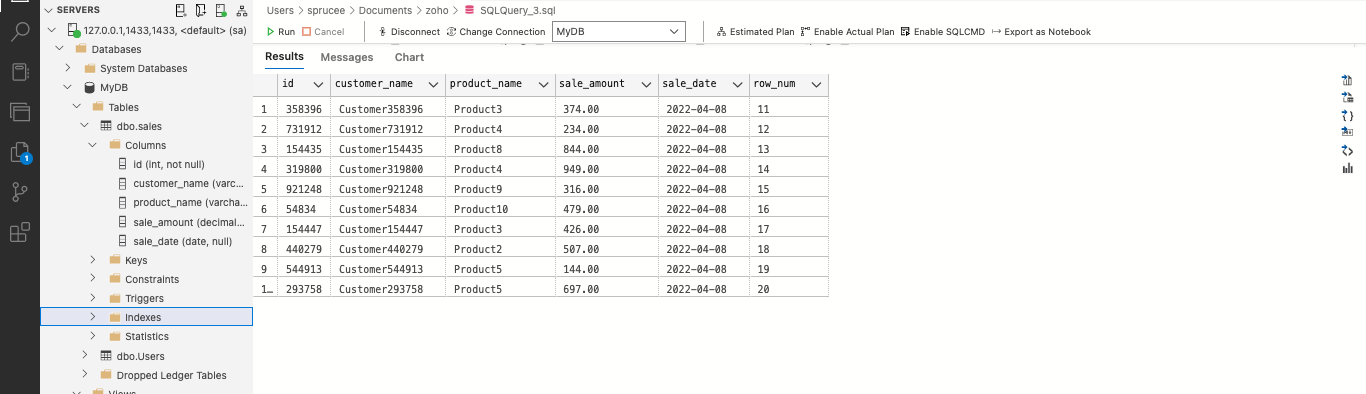
Рис. 2: Ограничение данных с помощью оконной функции
В качестве альтернативы разбивка на страницы разделяет запросы на меньшие наборы, чтобы ограничить количество данных, возвращаемых запросом, повышая производительность запроса. Приведенный ниже код возвращает только 10 строк одновременно.:
DECLARE @page_number AS INT; SET @page_number = 2; SELECT * FROM sales ORDER BY sale_date OFFSET (@page_number - 1) * 10 ROWS FETCH NEXT 10 ROWS ONLY
Эти методы ограничения данных могут значительно повысить производительность SQL-запросов при работе с большими наборами данных.
Индексирование
Индексирование — важнейший метод повышения производительности SQL-запросов к большим таблицам. Оно создает указатели на данные таблицы, ускоряя поиск данных. Индексы удобны при работе с большими наборами данных, поскольку они помогают точно определить, где запрос должен искать информацию, уменьшая объем данных, которые должен сканировать запрос.
Однако создание индексов для всех столбцов таблицы не всегда является лучшим решением. Важно определить, а затем создать отсутствующие индексы или исправить неправильные. При выполнении запроса можно использовать план выполнения, предоставляемый SQL Server Management Studio или Azure Data Studio. План выполнения выдает предупреждение об отсутствии индекса, чтобы вы знали, какое из них исправить.
Например, предположим, вы хотите получить одно имя клиента из вашей таблицы продаж. Возможно, вам придется сканировать миллион строк, чтобы найти клиента с именем “Customer10098”. Выполнение этого запроса может привести к потере времени и ресурсов, если индекс отсутствует. Вместо того, чтобы фокусироваться на целевом столбце, запрос должен сканировать все эти данные, чтобы найти то, что ему нужно.
Вы можете использовать план выполнения для определения и создания отсутствующего индекса. Сначала нажмите CTRL + M в Windows или CMD + M на Mac, чтобы открыть план выполнения. Затем выполните приведенный ниже запрос:
SELECT * FROM sales WHERE customer_name = 'Customer10098'
После запуска запроса план выполнения показывает, что на операцию сканирования таблицы ушло 95% от общей стоимости запроса. Щелкните операцию сканирования таблицы. Этот пример показывает, что запрос прочитал 1 000 000 строк, что больше, чем необходимо:
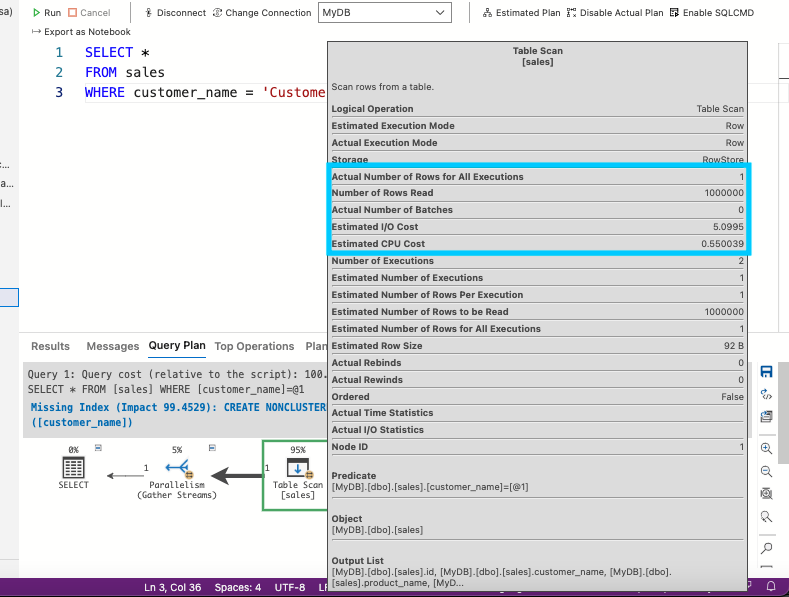
Рис. 3: Выполнение операции сканирования таблицы
Создание индекса в столбце customer_name оптимизирует запрос. В плане выполнения отображается предупреждение о отсутствующем индексе и предлагается, как создать индекс:
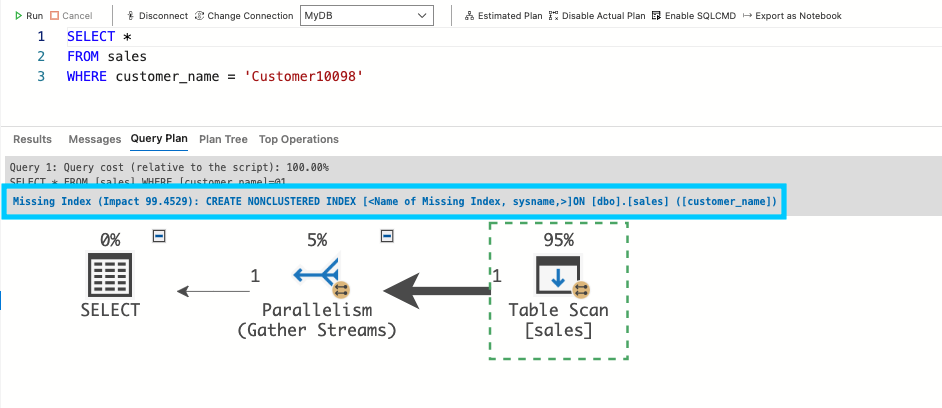
Рис. 4: Определение отсутствующего индекса
Нажмите на предупреждение о отсутствующем индексе, чтобы просмотреть пример кода для создания индекса:
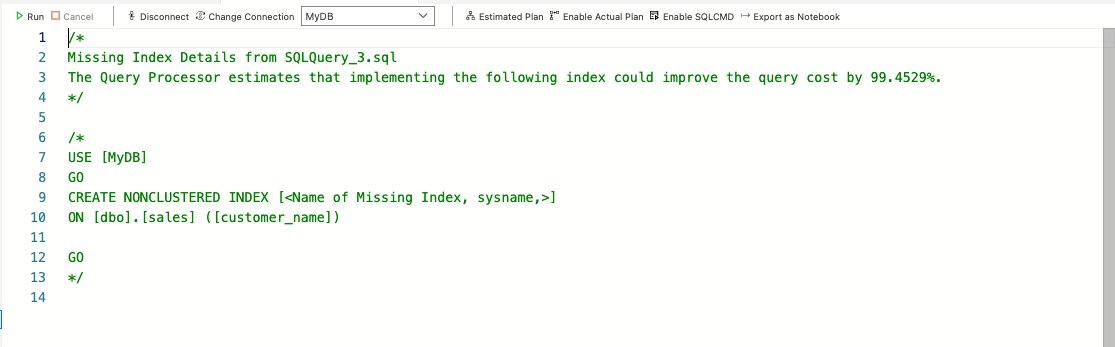
Рис. 5: Предложение по отсутствующему индексу
Для улучшения запросов можно создать два типа индексов: кластеризованные и некластеризованные. Таблица может иметь только один кластеризованный индекс, который определяет физический порядок данных. Некластеризованный индекс отделен от таблицы, сохраняя копию индексированных столбцов и указывая на исходные данные.
Кластеризованные индексы идеально подходят для часто просматриваемых столбцов, таких как первичные ключи, которые часто соединяют таблицы. Некластеризованные индексы полезны для столбцов, по которым запросы обычно выполняют поиск, но не обязательно для объединения таблиц. В этом примере используется некластеризованный индекс.
Чтобы создать индекс, раскомментируйте код, предложенный обработчиком запросов. Обязательно замените MyDB именем вашей базы данных:
USE [MyDB] GO CREATE NONCLUSTERED INDEX [ix_customer_name] ON [dbo].[sales] ([customer_name]) GO
После создания индекса повторно запустите запрос и сравните статистику, чтобы увидеть повышение производительности запроса:
SELECT * FROM sales WHERE customer_name = 'Customer10098'
Этот подход отображает ту же статистику, что и раньше, например, количество прочитанных строк. Однако на этот раз запрос отображает прочитанную 1 строку вместо 1 000 000:
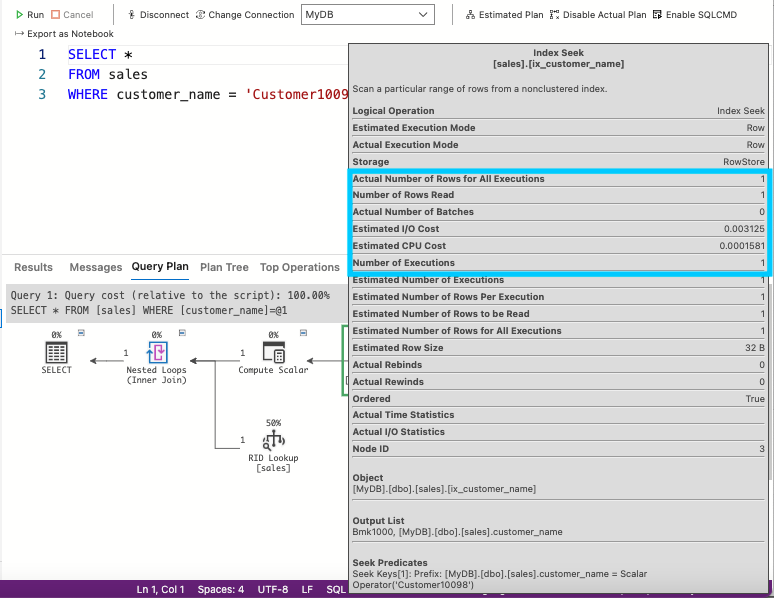
Рис. 6: Отображение статистики
Статистика показывает, что количество операций чтения, стоимость процессора и затраты на ввод-вывод значительно снизились. Теперь запрос использует индекс и работает намного лучше.
Параллельное выполнение
Параллельное выполнение повышает производительность запросов SQL Server за счет выполнения больших запросов на нескольких процессорах, разделяя работу между процессорами для более эффективной обработки больших объемов данных.
Значение MAXDOP определяет максимальное количество логических процессоров для запроса. По умолчанию оно равно 0. Итак, чтобы включить параллельное выполнение запросов и увеличить время обработки запросов, установите для параметра MAXDOP значение, большее 1.
Например, в приведенном ниже коде отключено параллельное выполнение, для параметра MAXDOP установлено значение 1. Этот параметр ограничивает количество процессоров, которые могут выполнять запрос, увеличивая время обработки запроса:
-- Disable parallel query execution SELECT customer_name, SUM(sale_amount) AS total_sales FROM sales WHERE YEAR(sale_date) = 2023 GROUP BY customer_name OPTION (MAXDOP 1)
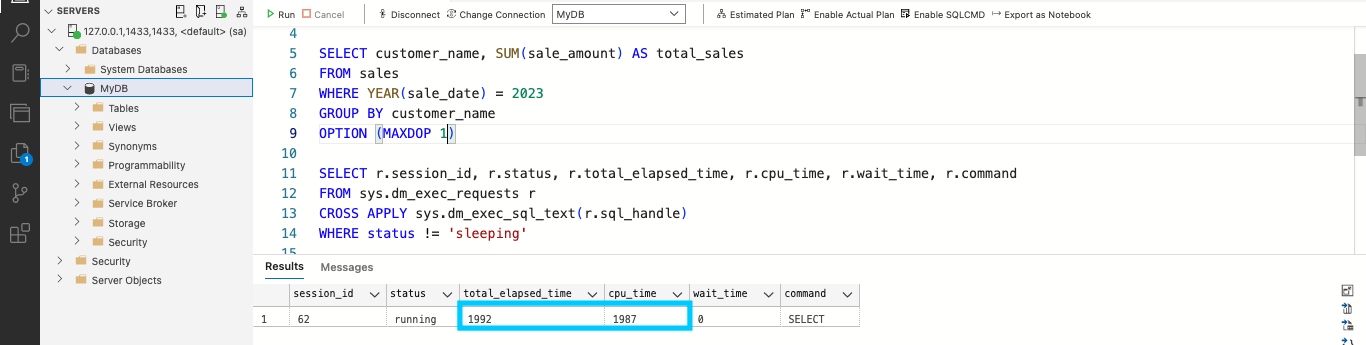
Рис. 7: Отключение параллельного выполнения
Статистика покажет, что total_elapsed_time и cpu_time высоки.
Чтобы оптимизировать этот запрос, увеличьте количество процессоров. Установите для параметра MAXDOP значение больше 1, используя приведенный ниже код:
-- Enable parallel query execution SELECT customer_name, SUM (sale_amount) AS total_sales FROM sales WHERE YEAR (sale_date) = 2023 GROUP BY customer_name OPTION (MAXDOP 4)
В коде MAXDOP установлено значение 4, поэтому SQL Server может использовать до 4 процессоров для выполнения запроса.
Дизайн запросов влияет на эффективность параллельного выполнения. Большие запросы, которые включают операции сортировки, группировки или объединения, являются хорошими кандидатами для распараллеливания.
Чтобы оптимизировать запросы для этого подхода к параллельному выполнению, упростите структуру запроса, используйте соответствующие индексы, избегайте блокирования операций и используйте подходящие типы данных. Сочетание этих методов с параллельным выполнением запроса может сократить время обработки запроса и повысить общую производительность системы.
Заключение
Оптимизация SQL-запросов для больших наборов данных необходима для повышения производительности приложения. Определите медленно выполняющиеся запросы, затем используйте оконные функции и разбивку на страницы, индексацию и параллельное выполнение, чтобы эти SQL-запросы выполнялись быстрее. Не забудьте оптимизировать запросы для параллельного выполнения и выбрать подходящий тип индекса для вашего набора данных.
Когда ваши запросы выполняются максимально быстро, ваши конечные пользователи быстро получают необходимую им информацию и остаются продуктивными.
Редактор: AndreyEx