15 типов баз данных и когда их использовать
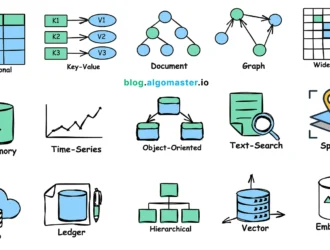
Базы данных — это основополагающие элементы системного проектирования, которые используются для эффективного хранения, управления и извлечения данных.
В этой статье мы рассмотрим 15 распространённых типов баз данных и обсудим, в каких случаях их следует использовать, а также приведём примеры.
1. Реляционные базы данных (СУБД)
Реляционные базы данных структурируют данные в виде одной или нескольких таблиц со строками и столбцами, каждая из которых идентифицируется уникальным ключом. Строки в таблице могут быть связаны со строками в других таблицах с помощью внешних ключей, устанавливающих между ними отношения.
Такая структура позволяет реляционным базам данных обрабатывать большие объёмы структурированных данных, обеспечивать целостность данных и поддерживать сложные запросы и транзакции ACID.
Они используют язык структурированных запросов (SQL) для определения, обработки и запроса данных, что делает их очень универсальными и широко используемыми в различных приложениях.
Распространенные варианты использования:
- Корпоративные приложения: для управления данными о клиентах, запасами, записями о сотрудниках и финансовыми транзакциями, где целостность данных и взаимосвязи имеют решающее значение.
- Платформы электронной коммерции: обработка каталогов товаров, заказов клиентов и платежных транзакций, требующих сложных запросов и обработки транзакций.
- Банковские и финансовые услуги: управление счетами, транзакциями и пользовательскими данными, где свойства ACID обеспечивают надёжность и согласованность финансовых операций.
Примеры: MySQL, PostgreSQL, Oracle Database.
2. Хранилище ключей-значений
Хранилища «ключ-значение» — это базы данных NoSQL, которые хранят данные в виде пар «ключ-значение», обеспечивая быстрый поиск значений по уникальным ключам.
В основном они используются, когда модель данных основана на парах «ключ-значение» и требует высокой масштабируемости, доступности и пропускной способности.
Однако они могут не подходить для приложений, требующих сложных запросов, связей между данными или надёжных гарантий согласованности.
Распространенные варианты использования:
- Сессионное хранилище: хранение и управление информацией о сеансе пользователя, такой как пользовательские настройки, корзины покупок или токены аутентификации в веб-приложениях.
- Кэширование: внедрение механизмов кэширования для повышения производительности веб-приложений за счет хранения часто используемых данных в памяти для быстрого доступа к ним.
- Обработка данных в реальном времени: хранилища «ключ-значение» могут быстро сохранять и извлекать данные для аналитики в реальном времени, обработки событий или очередей сообщений.
Примеры: Redis, DynamoDB.
3. Базы данных документов
Документальные базы данных, подмножество более широкого семейства NoSQL, предназначены для хранения, управления и извлечения информации, ориентированной на документы.
Эти базы данных обрабатывают данные в полуструктурированном формате, обычно в формате JSON, XML или BSON, что обеспечивает более гибкую схему, чем в традиционных реляционных базах данных.
Базы данных документов особенно полезны в сценариях, где модель данных часто меняется и где важна высокая скорость чтения и записи.
Однако они могут не подходить для работы с высокоструктурированными данными или сложными транзакциями, охватывающими несколько документов или коллекций.
Распространенные варианты использования:
- Платформы электронной коммерции: хранение каталогов товаров с различными характеристиками, отзывами пользователей и данными о запасах, что позволяет гибко представлять информацию о товарах.
- Системы управления контентом (CMS): идеально подходят для управления статьями, профилями пользователей и комментариями, где каждый фрагмент контента может храниться как документ.
- Аналитика в реальном времени и Интернет вещей: обработка различных структур данных, генерируемых устройствами Интернета вещей, и поддержка аналитики этих данных в реальном времени.
4. Графические базы данных
Графовые базы данных — это разновидность баз данных NoSQL, которые специализируются на хранении, управлении и обработке запросов к сложным сетям взаимосвязанных данных.
Они представляют данные в виде графов, состоящих из узлов (объектов), рёбер (связей между объектами) и свойств (информации, связанной с узлами и рёбрами).
Используя структуру графа, графовые базы данных обеспечивают эффективное перемещение, выполнение запросов и анализ взаимосвязанных данных.
Они очень полезны в таких приложениях, как социальные сети и системы рекомендаций.
Распространенные варианты использования:
- Социальные сети: управление профилями пользователей и их связями, включая такие функции, как рекомендации друзей и анализ социальных связей.
- Системы рекомендаций: анализ предпочтений клиентов, товарных запасов и истории покупок для составления персонализированных рекомендаций по продуктам или контенту.
- Графы знаний: создание обширных хранилищ взаимосвязанных данных для семантического поиска, поиска информации и систем поддержки принятия решений.
Примеры: Neo4j, Amazon Neptune.
5. Хранилища с широкими столбцами
Хранилища с широкими столбцами представляют собой тип баз данных NoSQL, оптимизированных для хранения и обработки больших объёмов данных на многих компьютерах.
Они организуют данные в таблицы с гибкой и динамичной структурой столбцов. Они предназначены для обработки крупномасштабных распределённых хранилищ данных и обеспечивают высокую масштабируемость и производительность.
Их архитектура, ориентированная на столбцы, гибкая схема и модель согласованности с возможностью восстановления делают их подходящими для приложений, которым требуется высокая скорость записи и обработка данных в реальном времени.
Однако они могут не подходить для случаев использования, требующих сложных объединений, высокой согласованности или строгих транзакций ACID.
Распространенные варианты использования:
- Веб-аналитика и отслеживание пользователей: идеально подходит для сбора и анализа данных о событиях в режиме реального времени, таких как веб-аналитика, журналы активности пользователей и мониторинг сети.
- Аналитика в реальном времени: они могут быстро собирать и анализировать данные, что делает их подходящими для информационных панелей, систем оповещения и оперативной аналитики.
Примеры:Apache Cassandra, Apache HBase, Google Bigtable.
6. Базы данных в памяти
Базы данных в оперативной памяти хранят данные непосредственно в оперативной памяти (ОЗУ) компьютера, в отличие от дисковых хранилищ.
Они предназначены для обеспечения чрезвычайно быстрого доступа к данным и низкой задержки за счёт устранения необходимости в операциях ввода-вывода на диске.
Базы данных в оперативной памяти особенно хорошо подходят для приложений, которым требуется обработка в реальном времени, высокоскоростные транзакции и доступ к данным с низкой задержкой, например для кэширования, аналитики в реальном времени и высокочастотной торговли.
Однако они стоят дорого, а основной памяти может не хватать для хранения всего набора данных.
Распространенные варианты использования:
- Онлайн-игры: для управления сеансами пользователей и состоянием игры в режиме реального времени, обеспечивая быстрый и отзывчивый игровой процесс.
- Высокочастотная торговля: позволяет совершать большое количество финансовых операций в секунду с минимальной задержкой.
Примеры: Redis, Memcached.
7. Базы данных временных рядов
Базы данных временных рядов (TSDB) специализируются на хранении, извлечении и управлении данными с отметками времени или временными рядами.
Данные временных рядов — это последовательность точек данных, собранных за определенные промежутки времени.
TSDB обычно используются в приложениях, которые генерируют и обрабатывают данные временных рядов, например в системах мониторинга, сенсорных сетях, финансовых торговых платформах и устройствах IoT (Интернета вещей).
Они обеспечивают необходимую производительность, масштабируемость и специализированные функции для работы с уникальными характеристиками данных временных рядов.
Распространенные варианты использования:
- Платформы для финансовой торговли: для отслеживания цен на акции, объёмов торгов и рыночных индикаторов с течением времени, что позволяет проводить анализ тенденций и использовать алгоритмические торговые стратегии.
- Управление данными IoT и датчиков: сбор и анализ данных с датчиков и устройств IoT, полезных для «умных» домов, промышленной автоматизации и мониторинга окружающей среды.
- Мониторинг производительности: в ИТ-инфраструктуре и сетевой инфраструктуре для отслеживания системных показателей (загрузка ЦП, потребление памяти, сетевой трафик) с течением времени, что помогает в планировании ресурсов и обнаружении аномалий.
Примеры: InfluxDB, TimescaleDB, Prometheus.
8. Объектно-ориентированные базы данных
Объектно-ориентированные базы данных (OODB) — это базы данных, которые хранят данные в виде объектов и управляют ими.
Эти объекты являются экземплярами классов, которые могут содержать как данные (атрибуты), так и поведение (методы), отражая структуру и концепции объектно-ориентированных языков программирования, таких как Java, C++ или Python.
OODB особенно хорошо подходят для приложений, в которых необходимы сложные модели данных или логика приложения в значительной степени опирается на объектно-ориентированные принципы.
Позволяя разработчикам работать напрямую с объектами в базе данных, OODB упрощают процесс разработки и обеспечивают более естественный и эффективный способ управления сложными структурами данных и взаимосвязями.
Распространенные варианты использования:
- Объектно-ориентированные приложения: приложения, разработанные с использованием ООП-языков, которым требуется бесперебойный механизм сохранения и извлечения объектов без необходимости их преобразования в другой формат (объектно-реляционное отображение).
- Мультимедийные базы данных: хранение, систематизация и извлечение мультимедийных элементов, таких как изображения, видео и аудиофайлы, которые могут извлекать выгоду из инкапсуляции как данных, так и функций (например, методов воспроизведения или редактирования).
Примеры: ObjectDB, db4o
9. Базы данных текстового поиска
Базы данных для текстового поиска — это специализированные системы, предназначенные для эффективного хранения, индексирования и поиска больших объёмов неструктурированных или частично структурированных текстовых данных.
Они обеспечивают быстрый и масштабируемый поиск, позволяя пользователям запрашивать и находить нужную информацию в обширных коллекциях документов, веб-страниц или другого текстового контента.
Распространенные варианты использования:
- Электронная коммерция: для поиска товаров в интернет-магазинах, чтобы помочь покупателям находить товары по описаниям, отзывам и метаданным.
- Веб-поиск: используется в поисковых системах, таких как Google, Bing и DuckDuckGo, для индексации и поиска огромного количества контента, доступного в интернете, что позволяет пользователям находить нужные веб-страницы по своим запросам.
- Анализ журналов: их можно использовать для индексирования и поиска больших объемов данных журналов, таких как журналы приложений или системные журналы, для устранения неполадок, мониторинга и аналитики.
Примеры: Elasticsearch, Apache Solr, Sphinx.
10. Пространственные базы данных
Пространственные базы данных предназначены для хранения, управления и анализа данных, представляющих географическую или пространственную информацию. Они расширяют возможности традиционных баз данных для работы со сложными пространственными типами данных, такими как точки, линии, многоугольники и другие геометрические фигуры, а также связанными с ними атрибутами и отношениями.
В пространственных базах данных используются эффективные методы индексирования, такие как R-деревья или квадродеревья, для оптимизации пространственных запросов и повышения производительности.
Они широко используются в сервисах, основанных на местоположении пользователя, таких как составление маршрутов, поиск ближайших ресторанов или отслеживание передвижения транспортных средств в режиме реального времени.
Распространенные варианты использования:
- Географические информационные системы (ГИС): для картографирования, анализа и управления данными, связанными с местами на поверхности Земли, для городского планирования, управления окружающей средой и планирования реагирования на чрезвычайные ситуации.
- Сервисы на основе определения местоположения (LBS): предоставляют услуги на основе определения местоположения пользователя, например, прокладывают маршруты и находят ближайшие рестораны.
- Логистика и транспорт: пространственные базы данных используются в логистических и транспортных системах для оптимизации маршрутов, отслеживания перемещений транспортных средств и анализа транспортных потоков.
Примеры: PostGIS (расширение для PostgreSQL), Oracle Spatial.
11. Хранилище данных больших двоичных объектов
Хранилища BLOB (двоичных больших объектов) предназначены для хранения, управления и извлечения больших блоков неструктурированных данных, таких как изображения, аудиофайлы, видео и документы.
В отличие от традиционных баз данных, которые работают со структурированными данными с чётко определёнными полями и записями, хранилища больших двоичных объектов оптимизированы для работы с большими и сложными массивами данных, которые не вписываются в стандартные схемы баз данных.
Они представляют собой масштабируемое, высокодоступное, надёжное и экономичное решение для управления большими объёмами неструктурированных данных.
Распространенные варианты использования:
- Сети доставки контента (CDN): для хранения и доставки больших медиафайлов, таких как видео и изображения, пользователям по всему миру.
- Хранилище больших данных: хранилища больших двоичных объектов могут хранить большие наборы данных, такие как файлы журналов, данные датчиков и научные данные, для анализа больших данных и конвейеров обработки.
- Резервное копирование и архивирование: хранилища BLOB-объектов обеспечивают надежное и масштабируемое решение для хранения резервных копий данных, архивов и долговременного хранения данных. Они также предлагают экономичные варианты хранения данных, к которым редко обращаются.
Примеры: Amazon S3, Azure Blob Storage, HDFS.
12. Базы данных бухгалтерской книги
Базы данных Ledger, также известные как блокчейн-базы данных, предназначены для хранения неизменяемых записей о транзакциях, к которым можно только добавлять новые.
Они сконструированы таким образом, чтобы после записи транзакции её нельзя было изменить или удалить, обеспечивая проверяемую и защищённую от несанкционированного доступа историю всех изменений с течением времени.
Базы данных Ledger особенно хорошо подходят для приложений, требующих высокого уровня доверия, прозрачности и неизменности.
Распространенные варианты использования:
- Управление цепочками поставок: базы данных могут отслеживать перемещение товаров и материалов по цепочке поставок, обеспечивая прозрачность и отслеживаемость.
- Здравоохранение: ведение записей о пациентах, форм согласия и историй болезни с помощью понятных, неизменяемых записей.
- Системы голосования: базы данных Ledger могут обеспечить безопасную и прозрачную платформу для проведения голосований, гарантируя целостность результатов голосования и предотвращая подтасовку или манипулирование.
Примеры: База данных Amazon Quantum Ledger (QLDB), Hyperledger Fabric.
13. Иерархические базы данных
Иерархические базы данных организуют данные в древовидную структуру, в которой данные хранятся в записях, и каждая запись имеет одну родительскую запись, но может иметь несколько дочерних записей, устанавливая связь «один ко многим» между записями.
Иерархические базы данных были популярны на заре вычислительной техники, особенно в мейнфреймах. Они широко использовались в файловых системах, где каталоги и файлы естественным образом вписывались в иерархическую структуру.
Однако они были в значительной степени вытеснены другими моделями баз данных, такими как реляционные базы данных и базы данных NoSQL, которые обеспечивают большую гибкость и лучше поддерживают сложные взаимосвязи.
Распространенные варианты использования:
- Организационные структуры: управление данными в организационных схемах, где каждый объект (например, сотрудник) имеет чёткую иерархическую связь.
- Файловые системы: Структура каталогов файловых систем — это классический пример иерархических данных, где папки содержат подпапки и файлы.
Примеры: IBM IMS, реестр Windows
14. Векторные базы данных
Векторные базы данных — это специализированные базы данных, предназначенные для хранения и поиска векторов, которые представляют собой массивы чисел, описывающих данные в многомерных пространствах.
Они оптимизированы для поиска по сходству и запросов ближайших соседей, что позволяет быстро находить похожие элементы на основе их векторных представлений.
Эти базы данных особенно актуальны в области машинного обучения и искусственного интеллекта (ИИ), где векторные представления обычно используются для кодирования характеристик различных типов данных, включая текст, изображения и аудио.
Распространенные варианты использования:
- Поиск изображений и видео: векторные базы данных позволяют находить изображения и видео по содержанию, сохраняя визуальные характеристики в виде многомерных векторов.
- Рекомендательные системы: представляя пользователей и объекты (например, товары, фильмы) в виде векторов, векторные базы данных могут быстро находить и рекомендовать объекты, схожие с интересами пользователя.
- Обнаружение аномалий: путем сравнения новых точек данных с известными нормальными образцами можно выявить аномалии на основе их различий.
Примеры: Faiss, Milvus, Pinecone.
15. Встроенные базы данных
Встраиваемые базы данных — это специализированные базы данных, предназначенные для тесной интеграции в программные приложения. В отличие от традиционных клиент-серверных баз данных, которые работают как отдельные процессы, встраиваемые базы данных связаны и работают как часть самого приложения.
Будучи тесно интегрированными в процесс работы приложения, они обеспечивают быстрый доступ к данным, занимают мало места и упрощают развёртывание.
Встроенные базы данных особенно полезны в условиях ограниченных ресурсов, когда полноценная клиент-серверная база данных не нужна или нецелесообразна.
Распространенные варианты использования:
- Игры: сохранение игровых состояний, прогресса игрока и настроек конфигурации непосредственно в игровом приложении.
- Настольные приложения: сохранение настроек конфигурации, пользовательских предпочтений и данных приложения локально на компьютере пользователя.
Примеры: SQLite, RocksDB, Berkeley DB.
Когда дело доходит до выбора базы данных, универсального решения не существует.
Выбор базы данных зависит от конкретного сценария использования, модели данных, требований к масштабируемости и бюджета.
Редактор: AndreyEx
